Home Field Advantage Again July 12, 2011
Posted by tomflesher in Baseball, Economics.Tags: attendance effects, Baseball, Giants, home field advantage, linear regression, probability, probit, statistics
add a comment
In an earlier post, I discussed the San Francisco Giants’ vaunted home field advantage and came to the conclusion that, while a home field advantage exists, it’s not related to the Giants scoring more runs at home than on the road. That was done with about 90 games’ worth of data. In order to come up with a more robust measure of home field advantage, I grabbed game-by-game data for the national league from the first half of the 2011 season and crunched some numbers.
I have two questions:
- Is there a statistically significant increase in winning probability while playing at home?
- Is that effect statistically distinct from any effect due to attendance?
- If it exists, does that effect differ from team to team? (I’ll attack this in a future post.)
Methodology: Using data with, among other things, per-game run totals, win-loss data, and attendance, I’ll run three regressions. The first will be a linear probability model of the form
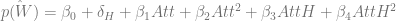
where 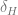

As such, I’ll also run a Probit model of the same equation to avoid problems caused by the simplicity of the linear probability model.
Finally, just as a sanity check, I’ll run the same regression, but for runs, instead of win probability. Since runs aren’t binary, I’ll use ordinary least squares, and also control for the possibility that games played in American League parks lead to higher run totals by controlling for the designated hitter:
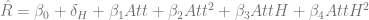
Since runs are a factor in winning, I have the same expectations about the signs of the beta values as above.
Results:
Regression 1 (Linear Probability Model):

So, my prediction about the attendance betas was incorrect, but only because I failed to account for the squared terms. The effect from home attendance increases as we approach full attendance; the effect from road attendance decreases at about the same rate. There’s still a net positive effect.
Regression 2 (Probit Model):

Note that in both cases, there’s a statistically significant 
Finally, the regression on runs:
Regression 3 (Predicted Runs):
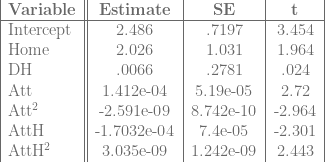
Again, with runs, there is a statistically significant effect from being at home, and a variety of possible attendance effects. For low attendance values, the Home effect is probably swamped by the negative attendance effect, but for high attendance games, the Home effect probably outweighs the attendance effect or the attendance effect becomes positive.
Again, the Home effect is statistically significant no matter which model we use, so at least in the National League, there is a noticeable home field advantage.
Quickie: MLB Playoffs by Pitching Statistics February 23, 2010
Posted by tomflesher in Baseball.Tags: Baseball, OLS, playoffs, probit, regression
add a comment
It’s cold out today. Last night, Buffalo was covered in a thin layer of freezing rain. I’m trying to stay warm by turning up my hot stove the way only an economist can – crunching the numbers on playoffs.
I’m re-using the dataset from my Cy Young Predictor a few entries ago in the interest of parsimony. It contains dummy variables teamdivwin and teamwildcard which take value 1 if the pitcher’s team won the division or the wildcard respectively. I then created a variable playoffs which took the value of the sum of teamdivwin and teamwildcard – just a playoff dummy variable.
Using a Probit model and a standard OLS regression model, I estimated the effects of individual pitching stats on playoffs. Neither model has very strong predictive value (linear has R-squared of about .05), which is unsurprising since it doesn’t take the team’s batting into account at all. None of the coefficient values are shocking – in the American League (designated as lg = 1), teams have a higher probability of making the playoffs because there are fewer teams, and although complete games appear to have a negative effect, the positive shutout effect more than makes up for that in both models. I’m interested in whether complete game wins and complete game losses have differential effects – that will probably be my next snowy-day project.
Results are behind the cut.
