Is scoring different in the AL and the NL? May 31, 2011
Posted by tomflesher in Baseball, Economics.Tags: American League, Baseball, baseball-reference.com, bunts, Chow test, linear regression, National League, R, structural break
trackback
The American League and the National League have one important difference. Specifically, the AL allows the use of a player known as the Designated Hitter, who does not play a position in the field, hits every time the pitcher would bat, and cannot be moved to a defensive position without forfeiting the right to use the DH. As a result, there are a couple of notable differences between the AL and the NL – in theory, there should be slightly more home runs and slightly fewer sacrifice bunts in the AL, since pitchers have to bat in the NL and they tend to be pretty poor hitters. How much can we quantify that difference? To answer that question, I decided to sample a ten-year period (2000 until 2009) from each league and run a linear regression of the form

Where runs are presumed to be a function of hits, doubles, triples, home runs, stolen bases, times caught stealing, walks, strikeouts, hit batsmen, bunts, and sacrifice flies. My expectations are:
- The sacrifice bunt coefficient should be smaller in the NL than in the AL – in the American League, bunting is used strategically, whereas NL teams are more likely to bunt whenever a pitcher appears, so in any randomly-chosen string of plate appearances, the chance that a bunt is the optimal strategy given an average hitter is much lower. (That is, pitchers bunt a lot, even when a normal hitter would swing away.) A smaller coefficient means each bunt produces fewer runs, on average.
- The strategy from league to league should be different, as measured by different coefficients for different factors from league to league. That is, the designated hitter rule causes different strategies to be used. I’ll use a technique called the Chow test to test that. That means I’ll run the linear model on all of MLB, then separately on the AL and the NL, and look at the size of the errors generated.
The results:
- In the AL, a sac bunt produces about .43 runs, on average, and that number is significant at the 95% level. In the NL, a bunt produces about .02 runs, and the number is not significantly different from saying that a bunt has no effect on run production.
- The Chow Test tells us at about a 90% confidence level that the process of producing runs in the AL is different than the process of producing runs in the NL. That is, in Major League Baseball, the designated hitter has a statistically significant effect on strategy. There’s structural break.
R code is behind the cut.
MLB:
> MLB.lm <- lm(R ~ H + X2B + X3B + HR + SB + CS + BB + SO + HBP + SH + SF) > summary(MLB.lm) Call: lm(formula = R ~ H + X2B + X3B + HR + SB + CS + BB + SO + HBP + SH + SF) Residuals: Min 1Q Median 3Q Max -7.002e+01 -1.174e+01 -9.314e-04 1.498e+01 6.732e+01 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -453.10394 39.32708 -11.521 < 2e-16 *** H 0.53819 0.02694 19.976 < 2e-16 *** X2B 0.14640 0.06384 2.293 0.0226 * X3B 0.69687 0.16290 4.278 2.57e-05 *** HR 0.93928 0.05036 18.653 < 2e-16 *** SB 0.05632 0.05459 1.032 0.3031 CS 0.03725 0.14576 0.256 0.7985 BB 0.31244 0.02168 14.410 < 2e-16 *** SO -0.02801 0.01513 -1.851 0.0652 . HBP 0.44309 0.10308 4.298 2.36e-05 *** SH -0.14210 0.06689 -2.124 0.0345 * SF 0.80263 0.18164 4.419 1.41e-05 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 22.46 on 288 degrees of freedom Multiple R-squared: 0.92, Adjusted R-squared: 0.9169 F-statistic: 301.1 on 11 and 288 DF, p-value: < 2.2e-16 > MLB.aov <- aov(R ~ H + X2B + X3B + HR + SB + CS + BB + SO + HBP + SH + SF) > summary(MLB.aov) Df Sum Sq Mean Sq F value Pr(>F) H 1 1111813 1111813 2204.2679 < 2.2e-16 *** X2B 1 21093 21093 41.8190 4.279e-10 *** X3B 1 6113 6113 12.1196 0.0005763 *** HR 1 380838 380838 755.0440 < 2.2e-16 *** SB 1 2775 2775 5.5022 0.0196709 * CS 1 776 776 1.5388 0.2158089 BB 1 121628 121628 241.1386 < 2.2e-16 *** SO 1 1740 1740 3.4504 0.0642589 . HBP 1 10494 10494 20.8045 7.534e-06 *** SH 1 3449 3449 6.8387 0.0093899 ** SF 1 9849 9849 19.5263 1.407e-05 *** Residuals 288 145265 504 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Created by Pretty R at inside-R.org
AL:
> AL.lm <- lm(R ~ H + X2B + X3B + HR + SB + CS + BB + SO + HBP + SH + SF) > summary(AL.lm) Call: lm(formula = R ~ H + X2B + X3B + HR + SB + CS + BB + SO + HBP + SH + SF) Residuals: Min 1Q Median 3Q Max -53.410 -13.107 -1.835 14.574 49.139 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -427.34031 55.72982 -7.668 3.85e-12 *** H 0.50747 0.03911 12.976 < 2e-16 *** X2B 0.21243 0.09538 2.227 0.02769 * X3B 0.85198 0.25274 3.371 0.00099 *** HR 0.89353 0.07306 12.231 < 2e-16 *** SB 0.13157 0.08673 1.517 0.13171 CS -0.41996 0.23826 -1.763 0.08034 . BB 0.34408 0.03256 10.566 < 2e-16 *** SO -0.04241 0.02433 -1.743 0.08368 . HBP 0.45716 0.15278 2.992 0.00332 ** SH 0.43101 0.19621 2.197 0.02984 * SF 0.67215 0.26915 2.497 0.01378 * --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 23.14 on 128 degrees of freedom Multiple R-squared: 0.9209, Adjusted R-squared: 0.9141 F-statistic: 135.5 on 11 and 128 DF, p-value: < 2.2e-16 > help() starting httpd help server ... done > help(lm) > AL.aov <- aov(R ~ H + X2B + X3B + HR + SB + CS + BB + SO + HBP + SH + SF) > summary(AL.aov) Df Sum Sq Mean Sq F value Pr(>F) H 1 499593 499593 932.8925 < 2.2e-16 *** X2B 1 17886 17886 33.3988 5.413e-08 *** X3B 1 15830 15830 29.5595 2.645e-07 *** HR 1 170063 170063 317.5592 < 2.2e-16 *** SB 1 1049 1049 1.9592 0.164021 CS 1 4373 4373 8.1658 0.004984 ** BB 1 75600 75600 141.1680 < 2.2e-16 *** SO 1 2009 2009 3.7505 0.054994 . HBP 1 5252 5252 9.8080 0.002154 ** SH 1 3234 3234 6.0391 0.015331 * SF 1 3340 3340 6.2368 0.013781 * Residuals 128 68548 536 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Created by Pretty R at inside-R.org
NL:
> NL.lm <- lm(R ~ H + X2B + X3B + HR + SB + CS + BB + SO + HBP + SH + SF) > summary(NL.lm) Call: lm(formula = R ~ H + X2B + X3B + HR + SB + CS + BB + SO + HBP + SH + SF) Residuals: Min 1Q Median 3Q Max -71.594 -9.621 1.258 11.946 58.529 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -474.75070 55.58292 -8.541 1.49e-14 *** H 0.52145 0.03830 13.616 < 2e-16 *** X2B 0.18340 0.09050 2.027 0.04450 * X3B 0.65062 0.21683 3.001 0.00316 ** HR 0.99662 0.07093 14.052 < 2e-16 *** SB 0.02082 0.06957 0.299 0.76515 CS 0.22201 0.18616 1.193 0.23496 BB 0.30956 0.03042 10.177 < 2e-16 *** SO -0.01041 0.02050 -0.508 0.61232 HBP 0.38324 0.13761 2.785 0.00605 ** SH 0.01567 0.12655 0.124 0.90164 SF 0.70346 0.24689 2.849 0.00501 ** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 21.14 on 148 degrees of freedom Multiple R-squared: 0.9171, Adjusted R-squared: 0.911 F-statistic: 148.9 on 11 and 148 DF, p-value: < 2.2e-16 > NL.aov <- aov(R ~ H + X2B + X3B + HR + SB + CS + BB + SO + HBP + SH + SF) > summary(NL.aov) Df Sum Sq Mean Sq F value Pr(>F) H 1 461597 461597 1032.5156 < 2.2e-16 *** X2B 1 4837 4837 10.8194 0.001255 ** X3B 1 290 290 0.6481 0.422080 HR 1 204654 204654 457.7763 < 2.2e-16 *** SB 1 1357 1357 3.0354 0.083546 . CS 1 490 490 1.0958 0.296899 BB 1 51509 51509 115.2181 < 2.2e-16 *** SO 1 15 15 0.0327 0.856799 HBP 1 3839 3839 8.5862 0.003925 ** SH 1 9 9 0.0206 0.886062 SF 1 3629 3629 8.1183 0.005007 ** Residuals 148 66165 447 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Created by Pretty R at inside-R.org
Chow’s Test:
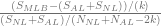



Since 1.9796 > 1.8232, the difference is not due to random variation and is significant at the 90% (but not 95%) level.

[…] and dirty check of this, I’d like to compare production in the 2000-2009 sample I used in a previous post to production in 2010. This will introduce a few problems, notably that using one year’s […]