Did Run Production Change in 2010? June 2, 2011
Posted by tomflesher in Baseball, Economics.Tags: Chow test, run production, Year of the Pitcher
add a comment
Part of the narrative of last year’s season was the compelling “Year of the Pitcher” storyline prompted by an unusual number of no-hitters and perfect games. Though it’s too early in the season to say the same thing is happening this year, a few bloggers have suggested that run production is down in 2011 and we might see the same sort of story starting again.
As a quick and dirty check of this, I’d like to compare production in the 2000-2009 sample I used in a previous post to production in 2010. This will introduce a few problems, notably that using one year’s worth of data for run production will lead to possibly spurious results for the 2010 data and that the success of the pitchers may be a result of the strategy used to generate runs. That is, if pitchers get better, and strategy doesn’t change, then we see pitchers taking advantage of inefficiencies in strategy. If batting strategy stays the same and pitchers take advantage of bad batting, then we should see a change in the structure of run production since the areas worked over by hitters – for example, walks and strikeouts – will see shifts in their relative importance in scoring runs.
Hypothesis: A regression model of runs against hits, doubles, triples, home runs, stolen bases, times caught stealing, walks, times hit by pitch, sacrifice bunts, and sacrifice flies using two datasets, one with team-level season-long data for each year from 2000 to 2009 and the other from 2010 only, will yield statistically similar beta coefficients.
Method: Chow test.
Result: There is a difference, significant at the 90% but not 95% level. That might be a result of a change in strategy or of pitchers exploiting strategic inefficiencies.
R code behind the cut.
Is scoring different in the AL and the NL? May 31, 2011
Posted by tomflesher in Baseball, Economics.Tags: American League, Baseball, baseball-reference.com, bunts, Chow test, linear regression, National League, R, structural break
1 comment so far
The American League and the National League have one important difference. Specifically, the AL allows the use of a player known as the Designated Hitter, who does not play a position in the field, hits every time the pitcher would bat, and cannot be moved to a defensive position without forfeiting the right to use the DH. As a result, there are a couple of notable differences between the AL and the NL – in theory, there should be slightly more home runs and slightly fewer sacrifice bunts in the AL, since pitchers have to bat in the NL and they tend to be pretty poor hitters. How much can we quantify that difference? To answer that question, I decided to sample a ten-year period (2000 until 2009) from each league and run a linear regression of the form

Where runs are presumed to be a function of hits, doubles, triples, home runs, stolen bases, times caught stealing, walks, strikeouts, hit batsmen, bunts, and sacrifice flies. My expectations are:
- The sacrifice bunt coefficient should be smaller in the NL than in the AL – in the American League, bunting is used strategically, whereas NL teams are more likely to bunt whenever a pitcher appears, so in any randomly-chosen string of plate appearances, the chance that a bunt is the optimal strategy given an average hitter is much lower. (That is, pitchers bunt a lot, even when a normal hitter would swing away.) A smaller coefficient means each bunt produces fewer runs, on average.
- The strategy from league to league should be different, as measured by different coefficients for different factors from league to league. That is, the designated hitter rule causes different strategies to be used. I’ll use a technique called the Chow test to test that. That means I’ll run the linear model on all of MLB, then separately on the AL and the NL, and look at the size of the errors generated.
The results:
- In the AL, a sac bunt produces about .43 runs, on average, and that number is significant at the 95% level. In the NL, a bunt produces about .02 runs, and the number is not significantly different from saying that a bunt has no effect on run production.
- The Chow Test tells us at about a 90% confidence level that the process of producing runs in the AL is different than the process of producing runs in the NL. That is, in Major League Baseball, the designated hitter has a statistically significant effect on strategy. There’s structural break.
R code is behind the cut.
More on Home Runs Per Game July 9, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, Chow test, home runs, Japan, Japanese baseball, R, Rays, regression, replication
add a comment
In the previous post, I looked at the trend in home runs per game in the Major Leagues and suggested that the recent deviation from the increasing trend might have been due to the development of strong farm systems like the Tampa Bay Rays’. That means that if the same data analysis process is used on data in an otherwise identical league, we should see similar trends but no dropoff around 1995. As usual, for replication purposes I’m going to use Japan’s Pro Baseball leagues, the Pacific and Central Leagues. They’re ideal because, just like the American Major Leagues, one league uses the designated hitter and one does not. There are some differences – the talent pool is a bit smaller because of the lower population base that the leagues draw from, and there are only 6 teams in each league as opposed to MLB’s 14 and 16.
As a reminder, the MLB regression gave us a regression equation of

where 
Just examining the data on home runs per game from the Japanese leagues, the trend looks significantly differe nt. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
nt. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
After running the same regression with t=1 in 1950, I got these results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.2462 | 0.0992 | 2.481 | 0.0148 | 0.9852 |
| t | 0.0478 | 0.0062 | 7.64 | 1.63E-11 | 1 |
| tsq | -0.0006 | 0.00009 | -7.463 | 3.82E-11 | 1 |
| DH | 0.0052 | 0.0359 | 0.144 | 0.8855 | 0.1145 |
This equation shows two things, one that surprises me and one that doesn’t. The unsurprising factor is the switching of signs for the t variables – we expected that based on the shape of the data. The surprising factor is that the designated hitter rule is insignificant. We can only be about 11% sure it’s significant. In addition, this model explains less of the variation than the MLB version – while that explained about 56% of the variation, the Japanese model has an 
There’s a slightly interesting pattern to the residual home runs per game (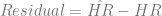
 it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
Incidentally, the Japanese league data is heteroskedastic (Breusch-Pagan test p-value .0796), so it might be better modeled using a generalized least squares formula, but doing so would have skewed the results of the replication.
In order to show that the parameters really are different, the appropriate test is Chow’s test for structural change. To clean it up, I’m using only the data from 1960 on. (It’s quick and dirty, but it’ll do the job.) Chow’s test takes

where 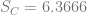
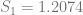
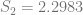





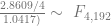


The critical value for 90% significance at 4 and 192 degrees of freedom would be 1.974 according to Texas A&M’s F calculator. That means we don’t have enough evidence that the parameters are different to treat them differently. This is probably an artifact of the small amount of data we have.
In the previous post, I looked at the trend in home runs per game in the Major Leagues and suggested that the recent deviation from the increasing trend might have been due to the development of strong farm systems like the Tampa Bay Rays’. That means that if the same data analysis process is used on data in an otherwise identical league, we should see similar trends but no dropoff around 1995. As usual, for replication purposes I’m going to use Japan’s Pro Baseball leagues, the Pacific and Central Leagues. They’re ideal because, just like the American Major Leagues, one league uses the designated hitter and one does not. There are some differences – the talent pool is a bit smaller because of the lower population base that the leagues draw from, and there are only 6 teams in each league as opposed to MLB’s 14 and 16.
As a reminder, the MLB regression gave us a regression equation of

where 
Just examining the data on home runs per game from the Japanese leagues, the trend looks significantly different. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
After running the same regression with t=1 in 1950, I got these results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.2462 | 0.0992 | 2.481 | 0.0148 | 0.9852 |
| t | 0.0478 | 0.0062 | 7.64 | 1.63E-11 | 1 |
| tsq | -0.0006 | 0.00009 | -7.463 | 3.82E-11 | 1 |
| DH | 0.0052 | 0.0359 | 0.144 | 0.8855 | 0.1145 |
This equation shows two things, one that surprises me and one that doesn’t. The unsurprising factor is the switching of signs for the t variables – we expected that based on the shape of the data. The surprising factor is that the designated hitter rule is insignificant. We can only be about 11% sure it’s significant. In addition, this model explains less of the variation than the MLB version – while that explained about 56% of the variation, the Japanese model has an 
There’s a slightly interesting pattern to the residual home runs per game ( it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
Incidentally, the Japanese league data is heteroskedastic (Breusch-Pagan test p-value .0796), so it might be better modeled using a generalized least squares formula, but doing so would have skewed the results of the replication.
In order to show that the parameters really are different, the appropriate test is Chow’s test for structural change. To clean it up, I’m using only the data from 1960 on. (It’s quick and dirty, but it’ll do the job.) Chow’s test takes
)/(k)}{(S_1+S_2)/(N_1+N_2-2k)} ~ F")
