Home Runs Per Game: A bit more in-depth December 23, 2011
Posted by tomflesher in Baseball, Economics.Tags: AR, autoregression, baseball-reference.com, home runs, home runs per plate appearance, linear regression, talent pool dilution
add a comment
I know I’ve done this one before, but in my defense, it was a really bad model.
I made some odd choices in modeling run production in that post. The first big questionable choice was to detrend according to raw time. That might make sense starting with a brand-new league, where we’d expect players to be of low quality and asymptotically approach a true level of production – a quadratic trend would be an acceptable model of dynamics in that case. That’s not a sensible way to model the major leagues, though; even though there’s a case to be made that players being in better physical condition will lead to better production, there’s no theoretical reason to believe that home run production will grow year over year.
So, let’s cut to the chase: I’m trying to capture a few different effects, and so I want to start by running a linear regression of home runs on a couple of controlling factors. Things I want to capture in the model:
- The DH. This should have a positive effect on home runs per game.
- Talent pool dilution. There are competing effects – more batters should mean that the best batters are getting fewer plate appearances, as a percentage of the total, but at the same time, more pitchers should mean that the best pitchers are facing fewer batters as a percentage of the total. I’m including three variables: one for the number of batters and one for the number of pitchers, to capture those effects individually, and one for the number of teams in the league. (All those variables are in natural logarithm form, so the interpretation will be that a 1% change in the number of batters, pitchers, or teams will have an effect on home runs.) The batting effect should be negative (more batters lead to fewer home runs); the pitching effect should be positive (more pitchers mean worse pitchers, leading to more home runs); the team effect could go either way, depending on the relative strengths of the effects.
- Trends in strategy and technology. I can’t theoretically justify a pure time trend, but I also can’t leave out trends entirely. Training has improved. Different training regimens become popular or fade away, and some strategies are much different than in previous years. I’ll use an autoregressive process to model these.
My dependent variable is going to be home runs per plate appearance. I chose HR/PA for two reasons:
- I’m using Baseball Reference’s AL and NL Batting Encyclopedias, which give per-game averages; HR per game/PA per game will wash out the per-game adjustments.
- League HR/PA should show talent pool dilution as noted above – the best hitters get the same plate appearances but their plate appearances will make up a smaller proportion of the total. I’m using the period from 1955 to 2010.
After dividing home runs per game by plate appearances per game, I used R to estimate an autoregressive model of home runs per plate appearance. That measures whether a year with lots of home runs is followed by a year with lots of home runs, whether it’s the reverse, or whether there’s no real connection between two consecutive years. My model took the last three years into account:

Since the model doesn’t fit perfectly, there will be an “error” term, 
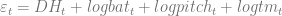
The results:

The DH and batter effects aren’t statistically different from zero, surprisingly; the pitching effect and the team effect are both significant at the 95% level. Interestingly, the team effect and the pitching effect have opposite signs, meaning that there’s some factor in increasing the number of teams that doesn’t relate purely to pitching or batting talent pool dilution.
For the record, fitted values of innovations correlate fairly highly with HR/PA: the correlation is about .70, despite a pretty pathetic R-squared of .08.
Padre Differential July 11, 2011
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, linear regression, National League, Padre Differential, Padres, Phillies, runs allowed, runs scored, statistics
1 comment so far
I was all set to fire up the Choke Index again this year. Unfortunately, Derek Jeter foiled my plan by making his 3000th hit right on time, so I can’t get any mileage out of that. Perhaps Jim Thome will start choking around #600 – but, frankly, I hope not. Since Jeter had such a callous disregard for the World’s Worst Sports Blog’s material, I’m forced to make up a new statistic.
This actually plays into an earlier post I made, which was about home field advantage for the Giants. It started off as a very simple regression for National League teams to see if the Giants’ pattern – a negative effect on runs scored at home, no real effect from the DH – held across the league. Those results are interesting and hold with the pattern that we’ll see below – I’ll probably slice them into a later entry.
The first thing I wanted to do, though, was find team effects on runs scored. Basically, I want to know how many runs an average team of Greys will score, how many more runs they’ll score at home, how many more runs they’ll score on the road if they have a DH, and then how many more runs the Phillies, the Mets, or any other team will score above their total. I’m doing this by converting Baseball Reference’s schedules and results for each team through their last game on July 10 to a data file, adding dummy variables for each team, and then running a linear regression of runs scored by each team against dummy variables for playing at home, playing with a DH, and the team dummies. In equation form,

For technical reasons, I needed to leave a team out, and so I chose the team that had the most negative coefficient: the Padres. Basically, then, the 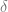

That is, the Padre Differential shows whether a team’s per-game run differential is higher or lower than the Padres’.
The table below shows each team in the National League, sorted by Padre Differential. By definition, San Diego’s Padre Differential is zero. ‘Sig95’ represents whether or not the value is statistically significant at the 95% level.

Unsurprisingly, the Phillies – the best team in baseball – have the highest Padre Differential in the league, with over 1.3 runs on average better than the Padres. Houston, in the cellar of the NL Central, is the worst team in the league and is .8 runs worse than the Padres per game. Florida and Chicago are both worse than the Padres and are both close to (Florida, 43) or below (Chicago, 37) the Padres’ 40-win total.
June Wins Above Expectation July 1, 2011
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, statistics, wins above expectation
add a comment
Even though I’ve conjectured that team-level wins above expectation are more or less random, I’ve seen a few searches coming in over the past few days looking for them. With that in mind, I constructed a table (with ample help from Baseball-Reference.com) of team wins, losses, Pythagorean expectations, wins above expectation, and Alpha.
Quick definitions:
- The Pythagorean Expectation (pyth%) is a tool that estimates what percentage of games a team should have won based on that team’s runs scored and runs allowed. Since it generates a percentage, Pythagorean Wins (pythW) are estimated by multiplying the Pythagorean expectation by the number of games a team has played.
- Wins Above Expectation (WAE) are wins in excess of the Pythagorean expected wins. It’s hypothesized by some (including, occasionally, me) that WAE represents an efficiency factor – that is, they represent wins in games that the team “shouldn’t” have won, earned through shrewd management or clutch play. It’s hypothesized by others (including, occasionally, me) that WAE represent luck.
- Alpha is a nearly useless statistic representing the percentage of wins that are wins above expectation. Basically, W-L% = pyth% + Alpha. It’s an accounting artifact that will be useful in a long time series to test persistence of wins above expectation.
The results are not at all interesting. The top teams in baseball – the Yankees, Red Sox, Phillies, and Braves – have either negative WAE (that is, wins below expectation) or positive WAE so small that they may as well be zero (about 2 wins in the Phillies’ case and half a win in the Braves’). The Phillies’ extra two wins are probably a mathematical distortion due to Roy Halladay‘s two tough losses and two no-decisions in quality starts compared with only two cheap wins (and both of those were in the high 40s for game score). In fact, Phildaelphia’s 66-run differential, compared with the Yankees’ 115, shows the difference between the two teams’ scoring habits. The Phillies have the luxury of relying on low run production (they’ve produced about 78% of the Yankees’ production) due to their fantastic pitching. On the other hand, the Yankees are struggling with a 3.53 starters’ ERA including Ivan Nova and AJ Burnett, both over 4.00, as full-time starters. The Phillies have three pitchers with 17 starts and an ERA under 3.00 (Halladay, Cliff Lee, and Cole Hamels) and Joe Blanton, who has an ERA of 5.50, has only started 6 games. Even with Blanton bloating it, the Phillies’ starer ERA is only 2.88.
That doesn’t, though, make the Yankees a badly-managed team. In fact, there’s an argument that the Yankees are MORE efficient because they’re leading their league, just as the Phillies are, with a much worse starting rotation, through constructing a team that can balance itself out.
That’s the problem with wins above expectation – they lend themselves to multiple interpretations that all seem equally valid.
Tables are behind the cut. (more…)
Is scoring different in the AL and the NL? May 31, 2011
Posted by tomflesher in Baseball, Economics.Tags: American League, Baseball, baseball-reference.com, bunts, Chow test, linear regression, National League, R, structural break
1 comment so far
The American League and the National League have one important difference. Specifically, the AL allows the use of a player known as the Designated Hitter, who does not play a position in the field, hits every time the pitcher would bat, and cannot be moved to a defensive position without forfeiting the right to use the DH. As a result, there are a couple of notable differences between the AL and the NL – in theory, there should be slightly more home runs and slightly fewer sacrifice bunts in the AL, since pitchers have to bat in the NL and they tend to be pretty poor hitters. How much can we quantify that difference? To answer that question, I decided to sample a ten-year period (2000 until 2009) from each league and run a linear regression of the form

Where runs are presumed to be a function of hits, doubles, triples, home runs, stolen bases, times caught stealing, walks, strikeouts, hit batsmen, bunts, and sacrifice flies. My expectations are:
- The sacrifice bunt coefficient should be smaller in the NL than in the AL – in the American League, bunting is used strategically, whereas NL teams are more likely to bunt whenever a pitcher appears, so in any randomly-chosen string of plate appearances, the chance that a bunt is the optimal strategy given an average hitter is much lower. (That is, pitchers bunt a lot, even when a normal hitter would swing away.) A smaller coefficient means each bunt produces fewer runs, on average.
- The strategy from league to league should be different, as measured by different coefficients for different factors from league to league. That is, the designated hitter rule causes different strategies to be used. I’ll use a technique called the Chow test to test that. That means I’ll run the linear model on all of MLB, then separately on the AL and the NL, and look at the size of the errors generated.
The results:
- In the AL, a sac bunt produces about .43 runs, on average, and that number is significant at the 95% level. In the NL, a bunt produces about .02 runs, and the number is not significantly different from saying that a bunt has no effect on run production.
- The Chow Test tells us at about a 90% confidence level that the process of producing runs in the AL is different than the process of producing runs in the NL. That is, in Major League Baseball, the designated hitter has a statistically significant effect on strategy. There’s structural break.
R code is behind the cut.
Weird Pitching Decisions Almanac in 2010 December 24, 2010
Posted by tomflesher in Baseball.Tags: baseball-reference.com, Carl Pavano, Cheap Wins, Clayton Kershaw, Colby Lewis, Cubs, Felix Hernandez, Francisco Rodriguez, Hiroki Kuroda, Jeremy Affeldt, John Lackey, Justin Verlander, Mariners, Phil Hughes, Red Sox, Rodrigo Lopez, Roy Oswalt, Royals, Tommy Hanson, Tough Losses, Tyler Clippard, vulture wins
1 comment so far
I’m a big fan of weird pitching decisions. A pitcher with a lot of tough losses pitches effectively but stands behind a team with crappy run support. A pitcher with a high proportion of cheap wins gets lucky more often than not. A reliever with a lot of vulture wins might as well be taking the loss.
In an earlier post, I defined a tough loss two ways. The official definition is a loss in which the starting pitcher made a quality start – that is, six or more innings with three or fewer runs. The Bill James definition is the same, except that James defines a quality start as having a game score of 50 or higher. In either case, tough losses result from solid pitching combined with anemic run support.
This year’s Tough Loss leaderboard had 457 games spread around 183 pitchers across both leagues. The Dodgers’ Hiroki Kuroda led the league with a whopping eight starts with game scores of 50 or more. He was followed by eight players with six tough losses, including Justin Verlander, Carl Pavano, Roy Oswalt, Rodrigo Lopez, Colby Lewis, Clayton Kershaw, Felix Hernandez, and Tommy Hanson. Kuroda’s Dodgers led the league with 23 tough losses, followed by the Mariners and the Cubs with 22 each.
There were fewer cheap wins, in which a pitcher does not make a quality start but does earn the win. The Cheap Win leaderboard had 248 games and 136 pitchers, led by John Lackey with six and Phil Hughes with 5. Hughes pitched to 18 wins, but Lackey’s six cheap wins were almost half of his 14-win total this year. That really shows what kind of run support he had. The Royals and the Red Sox were tied for first place with 15 team cheap wins each.
Finally, a vulture win is one for the relievers. I define a vulture win as a blown save and a win in the same game, so I searched Baseball Reference for players with blown saves and then looked for the largest number of wins. Tyler Clippard was the clear winner here. In six blown saves, he got 5 vulture wins. Francisco Rodriguez and Jeremy Affeldt each deserve credit, though – each had three blown saves and converted all three for vulture wins. (When I say “converted,” I mean “waited it out for their team to score more runs.”)
Diagnosing the AL December 22, 2010
Posted by tomflesher in Baseball, Economics.Tags: 2010, American League, baseball-reference.com, R, regression, statistics, Year of the Pitcher
add a comment
In the previous post, I crunched some numbers on a previous forecast I’d made and figured out that it was a pretty crappy forecast. (That’s the fun of forecasting, of course – sometimes you’re right and sometimes you’re wrong.) The funny part of it, though, is that the predicted home runs per game for the American League was so far off – 3.4 standard errors below the predicted value – that it’s highly unlikely that the regression model I used controls for all relevant variables. That’s not surprising, since it was only a time trend with a dummy variable for the designated hitter.
There are a couple of things to check for immediately. The first is the most common explanation thrown around when home runs drop – steroids. It seems to me that if the drop in home runs were due to better control of performance-enhancing drugs, then it should mostly be home runs that are affected. For example, intentional walks should probably be below expectation, since intentional walks are used to protect against a home run hitter. Unintentional walks should probably be about as expected, since walks are a function of plate discipline and pitcher control, not of strength. On-base percentage should probably drop at a lower magnitude than home runs, since some hits that would have been home runs will stay in the park as singles, doubles, or triples rather than all being fly-outs. There will be a drop but it won’t be as big. Finally, slugging average should drop because a loss in power without a corresponding increase in speed will lower total bases.
I’ll analyze these with pretty new R code behind the cut.
What Happened to Home Runs This Year? December 22, 2010
Posted by tomflesher in Baseball, Economics.Tags: baseball-reference.com, forecasting, home runs, R, regression, standard error, statistics, time series, Year of the Pitcher
1 comment so far
I was talking to Jim, the writer behind Apparently, I’m An Angels Fan, who’s gamely trying to learn baseball because he wants to be just like me. Jim wondered aloud how much the vaunted “Year of the Pitcher” has affected home run production. Sure enough, on checking the AL Batting Encyclopedia at Baseball-Reference.com, production dropped by about .15 home runs per game (from 1.13 to .97). Is that normal statistical variation or does it show that this year was really different?
In two previous posts, I looked at the trend of home runs per game to examine Stuff Keith Hernandez Says and then examined Japanese baseball’s data for evidence of structural break. I used the Batting Encyclopedia to run a time-series regression for a quadratic trend and added a dummy variable for the Designated Hitter. I found that the time trend and DH control account for approximately 56% of the variation in home runs per year, and that the functional form is
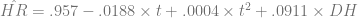
with t=1 in 1955, t=2 in 1956, and so on. That means t=56 in 2010. Consequently, we’d expect home run production per game in 2010 in the American League to be approximately

That means we expected production to increase this year and it dropped precipitously, for a residual of -.28. The residual standard error on the original regression was .1092, so on 106 degrees of freedom, so the t-value using Texas A&M’s table is 1.984 (approximating using 100 df). That means we can be 95% confident that the actual number of home runs should fall within .1092*1.984, or about .2041, of the expected value. The lower bound would be about 1.05, meaning we’re still significantly below what we’d expect. In fact, the observed number is about 3.4 standard errors below the expected number. In other words, we’d expect that to happen by chance less than .1% (that is, less than one tenth of one percent) of the time.
Clearly, something else is in play.
Home Run Derby: Does it ruin swings? December 15, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, Chris Young, Corey Hart, David Ortiz, Hanley Ramirez, home run derby, home runs, Matt Holliday, Miguel Cabrera, Nick Swisher, Vernon Wells
add a comment
Earlier this year, there was a lot of discussion about the alleged home run derby curse. This post by Andy on Baseball-Reference.com asked if the Home Run Derby is bad for baseball, and this Hardball Times piece agrees with him that it is not. The standard explanation involves selection bias – sure, players tend to hit fewer home runs in the second half after they hit in the Derby, but that’s because the people who hit in the Derby get invited to do so because they had an abnormally high number of home runs in the first half.
Though this deserves a much more thorough macro-level treatment, let’s just take a look at the density of home runs in either half of the season for each player who participated in the Home Run Derby. Those players include David Ortiz, Hanley Ramirez, Chris Young, Nick Swisher, Corey Hart, Miguel Cabrera, Matt Holliday, and Vernon Wells.
For each player, plus Robinson Cano (who was of interest to Andy in the Baseball-Reference.com post), I took the percentage of games before the Derby and compared it with the percentage of home runs before the Derby. If the Ruined Swing theory holds, then we’d expect

The table below shows that in almost every case, including Cano (who did not participate), the density of home runs in the pre-Derby games was much higher than the post-Derby games.
| Player | HR Before | HR Total | g(Games) | g(HR) | Diff |
| Ortiz | 18 | 32 | 0.54321 | 0.5625 | 0.01929 |
| Hanley | 13 | 21 | 0.54321 | 0.619048 | 0.075838 |
| Swisher | 15 | 29 | 0.537037 | 0.517241 | -0.0198 |
| Wells | 19 | 31 | 0.549383 | 0.612903 | 0.063521 |
| Holliday | 16 | 28 | 0.54321 | 0.571429 | 0.028219 |
| Hart | 21 | 31 | 0.549383 | 0.677419 | 0.128037 |
| Cabrera | 22 | 38 | 0.530864 | 0.578947 | 0.048083 |
| Young | 15 | 27 | 0.549383 | 0.555556 | 0.006173 |
| Cano | 16 | 29 | 0.537037 | 0.551724 | 0.014687 |
Is this evidence that the Derby causes home run percentages to drop off? Certainly not. There are some caveats:
- This should be normalized based on games the player played, instead of team games.
- It would probably even be better to look at a home run per plate appearance rate instead.
- It could stand to be corrected for deviation from the mean to explain selection bias.
- Cano’s numbers are almost identical to Swisher’s. They play for the same team. If there was an effect to be seen, it would probably show up here, and it doesn’t.
Once finals are up, I’ll dig into this a little more deeply.
Quickie: Ryan Howard’s Choke Index October 25, 2010
Posted by tomflesher in Baseball.Tags: baseball-reference.com, binomial distribution, Choke Index, Phillies, Ryan Howard, statistics
1 comment so far
The Choke Index is alive and well.
Previous to 2010, Ryan Howard of the Philadelphia Phillies hit home runs in three consecutive postseasons. He managed 7 in his 140 plate appearances, averaging out to .05 home runs per plate appearance. Not too shabby. It’s a bit below his regular season rate of about .067, but there are a bunch of things that could account for that.
This year, Ryan made 38 plate appearances and hit a grand total of 0 home runs in the postseason. What’s the likelihood of that happening? I use the Choke Index (one minus the probability of hitting 0 home runs in a given number of plate appearances) to measure that. As always, the closer a player gets to 1, the more unlikely his homer-free streak is.
The binomial probability can be calculated using the formula

Or, since we’re looking for the probability of an event NOT occurring,

or
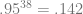
using his career postseason numbers. That means that Ryan Howard’s 2010 postseason Choke Index is .858. Pretty impressive!
