What Happened to Home Runs This Year? December 22, 2010
Posted by tomflesher in Baseball, Economics.Tags: baseball-reference.com, forecasting, home runs, R, regression, standard error, statistics, time series, Year of the Pitcher
trackback
I was talking to Jim, the writer behind Apparently, I’m An Angels Fan, who’s gamely trying to learn baseball because he wants to be just like me. Jim wondered aloud how much the vaunted “Year of the Pitcher” has affected home run production. Sure enough, on checking the AL Batting Encyclopedia at Baseball-Reference.com, production dropped by about .15 home runs per game (from 1.13 to .97). Is that normal statistical variation or does it show that this year was really different?
In two previous posts, I looked at the trend of home runs per game to examine Stuff Keith Hernandez Says and then examined Japanese baseball’s data for evidence of structural break. I used the Batting Encyclopedia to run a time-series regression for a quadratic trend and added a dummy variable for the Designated Hitter. I found that the time trend and DH control account for approximately 56% of the variation in home runs per year, and that the functional form is
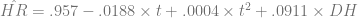
with t=1 in 1955, t=2 in 1956, and so on. That means t=56 in 2010. Consequently, we’d expect home run production per game in 2010 in the American League to be approximately

That means we expected production to increase this year and it dropped precipitously, for a residual of -.28. The residual standard error on the original regression was .1092, so on 106 degrees of freedom, so the t-value using Texas A&M’s table is 1.984 (approximating using 100 df). That means we can be 95% confident that the actual number of home runs should fall within .1092*1.984, or about .2041, of the expected value. The lower bound would be about 1.05, meaning we’re still significantly below what we’d expect. In fact, the observed number is about 3.4 standard errors below the expected number. In other words, we’d expect that to happen by chance less than .1% (that is, less than one tenth of one percent) of the time.
Clearly, something else is in play.

[…] know I’ve done this one before, but in my defense, it was a really bad […]