Did Run Production Change in 2010? June 2, 2011
Posted by tomflesher in Baseball, Economics.Tags: Chow test, run production, Year of the Pitcher
add a comment
Part of the narrative of last year’s season was the compelling “Year of the Pitcher” storyline prompted by an unusual number of no-hitters and perfect games. Though it’s too early in the season to say the same thing is happening this year, a few bloggers have suggested that run production is down in 2011 and we might see the same sort of story starting again.
As a quick and dirty check of this, I’d like to compare production in the 2000-2009 sample I used in a previous post to production in 2010. This will introduce a few problems, notably that using one year’s worth of data for run production will lead to possibly spurious results for the 2010 data and that the success of the pitchers may be a result of the strategy used to generate runs. That is, if pitchers get better, and strategy doesn’t change, then we see pitchers taking advantage of inefficiencies in strategy. If batting strategy stays the same and pitchers take advantage of bad batting, then we should see a change in the structure of run production since the areas worked over by hitters – for example, walks and strikeouts – will see shifts in their relative importance in scoring runs.
Hypothesis: A regression model of runs against hits, doubles, triples, home runs, stolen bases, times caught stealing, walks, times hit by pitch, sacrifice bunts, and sacrifice flies using two datasets, one with team-level season-long data for each year from 2000 to 2009 and the other from 2010 only, will yield statistically similar beta coefficients.
Method: Chow test.
Result: There is a difference, significant at the 90% but not 95% level. That might be a result of a change in strategy or of pitchers exploiting strategic inefficiencies.
R code behind the cut.
Spitballing: Blanton in the Phillies’ Rotation February 25, 2011
Posted by tomflesher in Baseball.Tags: Adam Eaton, Chan Ho Park, Clif Lee, Cole Hamels, Joe Blanton, Kyle Kendrick, Mets, Mike Pelfrey, Phillies, R.A. Dickey, Roy Halladay, Roy Oswalt, Spitballing, Year of the Pitcher
add a comment
The Phillies have one of the best rotations, on paper, in baseball today. Although some people are measured in their optimism, including Jayson Stark, I think the important thing to remember is that we’re arguing over whether they’re “the best ever,” not if they’re going to be competitive. Rotations that bring this kind of excitement at the beginning of the year are few and far between. The Mets, for example, aren’t drawing this kind of expectation – guys like R.A. Dickey and Mike Pelfrey are solid, but they don’t have the deserved reputations of Roy Halladay, Roy Oswalt, Cliff Lee, Cole Hamels, and Joe Blanton.
I’m hardly the first to say it, but Joe Blanton seems to be the odd man out. He’ll be making about $8.5 million next year. Blanton faced 765 batters last year, fourth behind Halladay, Hamels, and Kyle Kendrick. Immediately behind Blanton was Jamie Moyer with 460 batters faced. For the record, the fifth-most-active pitcher faced 362 batters in 2009 (Chan Ho Park) and 478 in 2008 (Adam Eaton). Let’s take that number and adjust it to about 550 batters faced, since Blanton will get more starts than most fifth starters and he’ll stay in longer since he’s a proven quantity. In a normal year, the Phils face about 6200 batters, so that means Blanton’s 550 will be about 9% of the team’s total. (That figure is robust even in last year’s Year of the Pitcher with depressed numbers of batters faced.)
According to J.C. Bradbury’s Hot Stove Economics, this yields an average marginal revenue product of 3.15 million. This figure is based on the average rate that pitchers prevent runs and the average revenue of an MLB team. Obviously, Blanton is a better than the average pitcher (ignoring his negative Wins Above Replacement last year) and the Phillies make more money than most teams, but this is a pretty damning figure.
The other thing to take into account is that Blanton’s marginal wins aren’t worth as much to the Phillies now that they have a four-ace rotation. He won’t get every start and he won’t be a 20-game winner. Even if he were, he’ll be providing insurance wins – he might have an extra ten wins over a AAA-level replacement, but chances are that those wins won’t make the difference between making the playoffs and missing them when you figure in the Phillies’ solid bullpen and run production.
Instead, let’s say Blanton goes to the White Sox, just to pick a team. Jake Peavy and Edwin Jackson combined for 765 batters faced, so plug Blanton in for Freddy Garcia with 671 batters faced – a worst-case scenario. That would be 10.85 % of the batters faced, bringing him up to about 3.8 million. In this case, though, you have a team who finished 6 games back and missed the playoffs. If you replace Garcia with Blanton, you stand a very good chance to make the playoffs. That’s another way of saying that the Phillies’ 6-game lead over Atlanta (the NL wild card team) was worth less than the Twins’ 6-game lead over the White Sox (when neither team had as many wins as the AL wild card).
Economists would refer to this as a diminishing marginal returns situation – when you have fewer wins, around the middle of the pack, each additional win is worth a little less. This captures the idea that taking a 110-win team and giving them 111 wins would cost a lot of money and not yield much extra benefit, but a 90-win team making 91 wins might let them overtake another team.
The upshot of all of this? Trade Blanton for prospects. Rely on the bullpen and develop a future starter. Roy Halladay won’t be competitive forever.
Diagnosing the AL December 22, 2010
Posted by tomflesher in Baseball, Economics.Tags: 2010, American League, baseball-reference.com, R, regression, statistics, Year of the Pitcher
add a comment
In the previous post, I crunched some numbers on a previous forecast I’d made and figured out that it was a pretty crappy forecast. (That’s the fun of forecasting, of course – sometimes you’re right and sometimes you’re wrong.) The funny part of it, though, is that the predicted home runs per game for the American League was so far off – 3.4 standard errors below the predicted value – that it’s highly unlikely that the regression model I used controls for all relevant variables. That’s not surprising, since it was only a time trend with a dummy variable for the designated hitter.
There are a couple of things to check for immediately. The first is the most common explanation thrown around when home runs drop – steroids. It seems to me that if the drop in home runs were due to better control of performance-enhancing drugs, then it should mostly be home runs that are affected. For example, intentional walks should probably be below expectation, since intentional walks are used to protect against a home run hitter. Unintentional walks should probably be about as expected, since walks are a function of plate discipline and pitcher control, not of strength. On-base percentage should probably drop at a lower magnitude than home runs, since some hits that would have been home runs will stay in the park as singles, doubles, or triples rather than all being fly-outs. There will be a drop but it won’t be as big. Finally, slugging average should drop because a loss in power without a corresponding increase in speed will lower total bases.
I’ll analyze these with pretty new R code behind the cut.
What Happened to Home Runs This Year? December 22, 2010
Posted by tomflesher in Baseball, Economics.Tags: baseball-reference.com, forecasting, home runs, R, regression, standard error, statistics, time series, Year of the Pitcher
1 comment so far
I was talking to Jim, the writer behind Apparently, I’m An Angels Fan, who’s gamely trying to learn baseball because he wants to be just like me. Jim wondered aloud how much the vaunted “Year of the Pitcher” has affected home run production. Sure enough, on checking the AL Batting Encyclopedia at Baseball-Reference.com, production dropped by about .15 home runs per game (from 1.13 to .97). Is that normal statistical variation or does it show that this year was really different?
In two previous posts, I looked at the trend of home runs per game to examine Stuff Keith Hernandez Says and then examined Japanese baseball’s data for evidence of structural break. I used the Batting Encyclopedia to run a time-series regression for a quadratic trend and added a dummy variable for the Designated Hitter. I found that the time trend and DH control account for approximately 56% of the variation in home runs per year, and that the functional form is
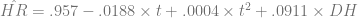
with t=1 in 1955, t=2 in 1956, and so on. That means t=56 in 2010. Consequently, we’d expect home run production per game in 2010 in the American League to be approximately

That means we expected production to increase this year and it dropped precipitously, for a residual of -.28. The residual standard error on the original regression was .1092, so on 106 degrees of freedom, so the t-value using Texas A&M’s table is 1.984 (approximating using 100 df). That means we can be 95% confident that the actual number of home runs should fall within .1092*1.984, or about .2041, of the expected value. The lower bound would be about 1.05, meaning we’re still significantly below what we’d expect. In fact, the observed number is about 3.4 standard errors below the expected number. In other words, we’d expect that to happen by chance less than .1% (that is, less than one tenth of one percent) of the time.
Clearly, something else is in play.
Matt Garza, Fifth No-Hitter of 2010 July 26, 2010
Posted by tomflesher in Baseball.Tags: Dallas Braden, Edwin Jackson, Matt Garza, no-hitters, Roy Halladay, Ubaldo Jimenez, Year of the Pitcher
1 comment so far
Tonight, Matt Garza pitched the fifth no-hitter of 2010. He joins Edwin Jackson, Roy Halladay, Dallas Braden, and Ubaldo Jimenez in the Year of the Pitcher club.
As I pointed out when Jackson hit his no-hitter, no-hit games are probably Poisson distributed. Let’s update the chart.
The Poisson distribution has probability density function

Maintaining our prior rate of 2.45 no-hitters per season, that means 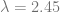

The probabilities remain the same:
| n | p | cumulative |
| 0 | 0.0863 | 0.0863 |
| 1 | 0.2114 | 0.2977 |
| 2 | 0.2590 | 0.5567 |
| 3 | 0.2115 | 0.7683 |
| 4 | 0.1296 | 0.8978 |
| 5 | 0.0635 | 0.9613 |
| 6 | 0.0259 | 0.9872 |
| 7 | 0.0091 | 0.9963 |
| 8 | 0.0028 | 0.9991 |
| 9 | 0.0008 | 0.9998 |
| 10 | 0.0002 | 1.0000 |
And though the expectation (E(49)) and cumulative expectation (C(49)) remain the same, the observed values shift slightly:
| E(49) | Observed | C(49) | Total |
| 4.23 | 5 | 4.23 | 5 |
| 10.36 | 11 | 14.59 | 16 |
| 12.69 | 8 | 27.28 | 24 |
| 10.36 | 17 | 37.65 | 41 |
| 6.35 | 1 | 43.99 | 42 |
| 3.11 | 5 | 47.10 | 47 |
| 1.27 | 1 | 48.37 | 48 |
| 0.44 | 0 | 48.82 | 48 |
| 0.14 | 1 | 48.95 | 49 |
| 0.04 | 0 | 48.99 | 49 |
| 0.01 | 0 | 49.00 | 49 |
The tailing observations (say, for 4+ no-hitters) don’t quite match the expected frequencies, but the cumulative values match quite nicely. There might be some unobserved variables that explain the weirdness in the upper tail. Still, cumulatively, we have 47 seasons with 5 or fewer no-hitters, which is almost exactly what’s expected. This is unusual, but not outside the realm of statistical expectation.
Back when it was hard to hit 55… July 8, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, home runs, R, regression, sabermetrics, Stuff Keith Hernandez Says, talent pool dilution, Willie Mays, Year of the Pitcher
add a comment
Last night was one of those classic Keith Hernandez moments where he started talking and then stopped abruptly, which I always like to assume is because the guys in the truck are telling him to shut the hell up. He was talking about Willie Mays for some reason, and said that Mays hit 55 home runs “back when it was hard to hit 55.” Keith coyly said that, while it was easy for a while, it was “getting hard again,” at which point he abruptly stopped talking.
Keith’s unusual candor about drug use and Mays’ career best of 52 home runs aside, this pinged my “Stuff Keith Hernandez Says” meter. After accounting for any time trend and other factors that might explain home run hitting, is there an upward trend? If so, is there a pattern to the remaining home runs?
The first step is to examine the data to see if there appears to be any trend. Just looking at it, there appears to be a messy U shape with a minimum around t=20, which indicates a quadratic trend. That means I want to include a term for time and a term for time squared.
Using the per-game averages for home runs from 1955 to 2009, I detrended the data using t=1 in 1955. I also had to correct for the effect of the designated hitter. That gives us an equation of the form
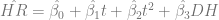
The results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.957 | 0.0328 | 29.189 | 0.0001 | 0.9999 |
| t | -0.0188 | 0.0028 | -6.738 | 0.0001 | 0.9999 |
| tsq | 0.0004 | 0.00005 | 8.599 | 0.0001 | 0.9999 |
| DH | 0.0911 | 0.0246 | 3.706 | 0.0003 | 0.9997 |
We can see that there’s an upward quadratic trend in predicted home runs that together with the DH rule account for about 56% of the variation in the number of home runs per game in a season (
Then, I needed to look at the difference between the predicted number of home runs per game and the actual number of home runs per game, which is accessible by subtracting
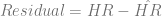
This represents the “abnormal” number of home runs per year. The question then becomes, “Is there a patt ern to the number of abnormal home runs?” There are two ways to answer this. The first way is to look at the abnormal home runs. Up until about t=40 (the mid-1990s), the abnormal home runs are pretty much scattershot above and below 0. However, at t=40, the residual jumps up for both leagues and then begins a downward trend. It’s not clear what the cause of this is, but the knee-jerk reaction is that there might be a drug use effect. On the other hand, there are a couple of other explanations.
ern to the number of abnormal home runs?” There are two ways to answer this. The first way is to look at the abnormal home runs. Up until about t=40 (the mid-1990s), the abnormal home runs are pretty much scattershot above and below 0. However, at t=40, the residual jumps up for both leagues and then begins a downward trend. It’s not clear what the cause of this is, but the knee-jerk reaction is that there might be a drug use effect. On the other hand, there are a couple of other explanations.
The most obvious is a boring old expansion effect. In 1993, the National League added two teams (the Marlins and the Rockies), and in 1998 each league added a team (the AL’s Rays and the NL’s Diamondbacks). Talent pool dilution has shown up in our discussion of hit batsmen, and I believe that it can be a real effect. It would be mitigated over time, however, by the establishment and development of farm systems, in particular strong systems like the one that’s producing good, cheap talent for the Rays.
Tough Losses July 8, 2010
Posted by tomflesher in Baseball.Tags: Baseball, baseball-reference.com, Dan Haren, Jon Niese, Roy Halladay, Roy Oswalt, Ubaldo Jimenez, weird lines, Year of the Pitcher, Yovani Gallardo
2 comments
Last night, Jonathon Niese pitched 7.2 innings of respectable work (6 hits, 3 runs, all earned, 1 walk, 8 strikeouts, 2 home runs, for a game score of 62) but still took the loss due to his unfortunate lack of run support – the Mets’ only run came in from an Angel Pagan solo homer. This is a prime example of what Bill James called a “Tough Loss”: a game in which the starting pitcher made a quality start but took a loss anyway.
There are two accepted measures of what a quality start is. Officially, a quality start is one with 6 or more innings pitched and 3 or fewer runs. Bill James’ definition used his game score statistic and used 50 as the cutoff point for a quality start. Since a pitcher gets 50 points for walking out on the mound and then adds to or subtracts from that value based on his performance, game score has the nice property of showing whether a pitcher added value to the team or not.
Using the game score definition, there were 393 losses in quality starts last year, including 109 by July 7th. Ubaldo Jimenez and Dan Haren led the league with 7, Roy Halladay had 6, and Yovani Gallardo (who’s quickly becoming my favorite player because he seems to show up in every category) was also up there with 6.
So far this year, though, it seems to be the Year of the Tough Loss. There have already been 230, and Roy Oswalt is already at the 6-tough-loss mark. Halladay is already up at 4. This is consistent with the talk of the Year of the Pitcher, with better pitching (and potentially less use of performance-enhancing drugs) leading to lower run support. That will require a bit more work to confirm, though.
