A fifteen-inning offensive drought July 18, 2011
Posted by tomflesher in Baseball.Tags: Jacoby Ellsbury, Rays, Red Sox, weird lines
2 comments
Last night’s ESPN game, between the Red Sox and the Rays, was a pitchers’ duel of the highest magnitude. John at Baseball Reference already looked for other games where both starters had game scores of 85 or higher, and neither team had to call on a position player to pitch, but I thought one of the most interesting things to happen was offensive in nature.
Neither team scored until the sixteenth inning, at which point Dustin Pedroia followed up a John Reddick walk, a Jason Varitek sacrifice, and a Marco Scutaro infield single (to move Reddick to third) with a single to right field. Every batter up to that point was productive and helped manufacture that run… except Jacoby Ellsbury, who flied out to left between Scutaro and Pedroia. In fact, every lineup spot had either a hit, a walk, or a productive out except for Ellsbury, who led off. (Granted, Varitek’s only productivity was his sacrifice, but that’s enough.) Ellsbury had 8 plate appearances, all of them at-bats, and didn’t reach base at all.
Even getting 8 plate appearances is rare. Since 2002 (and through July 7), only 403 batters have had 8 plate appearances, including a handful with 10 and quite a few with 9. All five of the 10-plate-appearance games took place on April 17, but some of them took place in 2008 and some in 2010. (Just an odd coincidence.) Of those 403, only 12 failed to reach base at all. Corey Patterson and Trot Nixon share the record for most plate appearances without reaching base, with 10.
Ellsbury’s streak of 8 plate appearances without reaching base is especially weird because he’s so talented. Ellsbury has a .370 OBP, meaning that on average he reaches base 37% of the time (or, he only gets sent back to the dugout 63% of the time). If we assume last night’s plate appearances were random draws, the probability of 8 times without reaching base would be

or, in English, vanishingly rare.
Chad Billingsley’s Home Run June 6, 2011
Posted by tomflesher in Baseball.Tags: Casey Blake, Chad Billingsley, Diamondbacks, Dodgers, James Loney, Keith Osik, Matt Kemp, Nationals, Nick Swisher, Pitchers batting, position players pitching, Rays, Reds, Travis Wood, Yankees, Zach Duke
add a comment
Chad Billingsley had what was by all accounts an unremarkable start on the mound last night: 5 IP, 8 H, 4 R, all of them earned, 3 walks, 3 strikeouts, 1 HBP. Considering that the Dodgers have seven tough losses already (only the Rays and the Nationals have more), this would ordinarily be a short entry commenting on how Billingsley needs some work.
Actually, scratch that. I wouldn’t make that entry – the folks over at Mike Scioscia’s Tragic Illness would.
Billingsley managed to earn a mention last night by hitting the second home run of his career (solo in the second) and going 2 for 2 with a walk. Billingsley’s Win Probability Added (WPA) from the plate was a team-leading .215 (Matt Kemp was second with .168). Of course, he evened that out with actually subtracting WPA as a pitcher. Still, his walk in the third forced Casey Blake in for a second RBI, and his double in the fifth brought James Loney home and ultimately pulled Reds starter Travis Wood out of the game.
Oddly, Wood himself managed a three-RBI night back on May 9, as did the Diamondbacks’ Zach Duke on May 28. Like Billingsley, both of them took the win in those games.
The most stylish home runs by pitchers happen when the player doesn’t even know he’s a pitcher, though – on April 13, 2009, Nick Swisher hit a home run in the top of the fourth inning while playing first base and then was called on to pitch the bottom of the 8th in a 15-5 loss to the Rays. He’s the only player in the last 10 years to start the game as a position player, hit a home run, and pitch. Admittedly, that’s a weird set of conditions. Luckily, there’s another instance that almost fits, so I don’t feel like I’m cheating. Keith Osik didn’t start on May 20, 2000, but came in as part of a triple-switch in the top of the 8th to play third base. Osik hit a two-run homer to bring Mike Benjamin home in the bottom of the 8th, then gave up 5 earned runs on 5 hits in the top of the 9th.
Hopefully Billingsley will repeat his performance at the plate and will continue cleaning up on the mound. Last night was his first Cheap Win of the year, and he already has two Tough Losses. Not a bad showing as far as ability goes.
More on Home Runs Per Game July 9, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, Chow test, home runs, Japan, Japanese baseball, R, Rays, regression, replication
add a comment
In the previous post, I looked at the trend in home runs per game in the Major Leagues and suggested that the recent deviation from the increasing trend might have been due to the development of strong farm systems like the Tampa Bay Rays’. That means that if the same data analysis process is used on data in an otherwise identical league, we should see similar trends but no dropoff around 1995. As usual, for replication purposes I’m going to use Japan’s Pro Baseball leagues, the Pacific and Central Leagues. They’re ideal because, just like the American Major Leagues, one league uses the designated hitter and one does not. There are some differences – the talent pool is a bit smaller because of the lower population base that the leagues draw from, and there are only 6 teams in each league as opposed to MLB’s 14 and 16.
As a reminder, the MLB regression gave us a regression equation of

where 
Just examining the data on home runs per game from the Japanese leagues, the trend looks significantly differe nt. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
nt. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
After running the same regression with t=1 in 1950, I got these results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.2462 | 0.0992 | 2.481 | 0.0148 | 0.9852 |
| t | 0.0478 | 0.0062 | 7.64 | 1.63E-11 | 1 |
| tsq | -0.0006 | 0.00009 | -7.463 | 3.82E-11 | 1 |
| DH | 0.0052 | 0.0359 | 0.144 | 0.8855 | 0.1145 |
This equation shows two things, one that surprises me and one that doesn’t. The unsurprising factor is the switching of signs for the t variables – we expected that based on the shape of the data. The surprising factor is that the designated hitter rule is insignificant. We can only be about 11% sure it’s significant. In addition, this model explains less of the variation than the MLB version – while that explained about 56% of the variation, the Japanese model has an 
There’s a slightly interesting pattern to the residual home runs per game (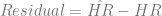
 it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
Incidentally, the Japanese league data is heteroskedastic (Breusch-Pagan test p-value .0796), so it might be better modeled using a generalized least squares formula, but doing so would have skewed the results of the replication.
In order to show that the parameters really are different, the appropriate test is Chow’s test for structural change. To clean it up, I’m using only the data from 1960 on. (It’s quick and dirty, but it’ll do the job.) Chow’s test takes

where 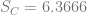
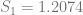
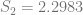





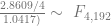


The critical value for 90% significance at 4 and 192 degrees of freedom would be 1.974 according to Texas A&M’s F calculator. That means we don’t have enough evidence that the parameters are different to treat them differently. This is probably an artifact of the small amount of data we have.
In the previous post, I looked at the trend in home runs per game in the Major Leagues and suggested that the recent deviation from the increasing trend might have been due to the development of strong farm systems like the Tampa Bay Rays’. That means that if the same data analysis process is used on data in an otherwise identical league, we should see similar trends but no dropoff around 1995. As usual, for replication purposes I’m going to use Japan’s Pro Baseball leagues, the Pacific and Central Leagues. They’re ideal because, just like the American Major Leagues, one league uses the designated hitter and one does not. There are some differences – the talent pool is a bit smaller because of the lower population base that the leagues draw from, and there are only 6 teams in each league as opposed to MLB’s 14 and 16.
As a reminder, the MLB regression gave us a regression equation of

where 
Just examining the data on home runs per game from the Japanese leagues, the trend looks significantly different. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
After running the same regression with t=1 in 1950, I got these results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.2462 | 0.0992 | 2.481 | 0.0148 | 0.9852 |
| t | 0.0478 | 0.0062 | 7.64 | 1.63E-11 | 1 |
| tsq | -0.0006 | 0.00009 | -7.463 | 3.82E-11 | 1 |
| DH | 0.0052 | 0.0359 | 0.144 | 0.8855 | 0.1145 |
This equation shows two things, one that surprises me and one that doesn’t. The unsurprising factor is the switching of signs for the t variables – we expected that based on the shape of the data. The surprising factor is that the designated hitter rule is insignificant. We can only be about 11% sure it’s significant. In addition, this model explains less of the variation than the MLB version – while that explained about 56% of the variation, the Japanese model has an 
There’s a slightly interesting pattern to the residual home runs per game ( it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
Incidentally, the Japanese league data is heteroskedastic (Breusch-Pagan test p-value .0796), so it might be better modeled using a generalized least squares formula, but doing so would have skewed the results of the replication.
In order to show that the parameters really are different, the appropriate test is Chow’s test for structural change. To clean it up, I’m using only the data from 1960 on. (It’s quick and dirty, but it’ll do the job.) Chow’s test takes
)/(k)}{(S_1+S_2)/(N_1+N_2-2k)} ~ F")
Edwin Jackson, Fourth No-Hitter of 2010 June 25, 2010
Posted by tomflesher in Baseball, Economics.Tags: baseball-reference.com, BayesBall, Dallas Braden, Diamondbacks, Edwin Jackson, no-hitters, poisson distribution, Rays, Roy Halladay, Ubaldo Jimenez
2 comments
Tonight, Edwin Jackson of the Arizona Diamondbacks pitched a no-hitter against the Tampa Bay Rays. That’s the fourth no-hitter of this year, following Ubaldo Jimenez and the perfect games by Dallas Braden and Roy Halladay.
Two questions come to mind immediately:
- How likely is a season with 4 no-hitters?
- Does this mean we’re on pace for a lot more?
The second question is pretty easy to dispense with. Taking a look at the list of all no-hitters (which interestingly enough includes several losses), it’s hard to predict a pattern. No-hitters aren’t uniformly distributed over time, so saying that we’ve had 4 no-hitters in x games doesn’t tell us anything meaningful about a pace.
The first is a bit more interesting. I’m interested in the frequency of no-hitters, so I’m going to take a look at the list of frequencies here and take a page from Martin over at BayesBall in using the Poisson distribution to figure out whether this is something we can expect.
The Poisson distribution takes the form

where 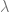

Using Martin’s numbers – 201506 opportunities for no-hitters and an average of 4112 games per season from 1961 to 2009 – I looked at the number of no-hitters since 1961 (120) and determined that an average season should return about 2.44876 no-hitters. That means
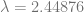
and

 Above is the distribution. p is the probability of exactly n no-hitters being thrown in a single season of 4112 games; cdf is the cumulative probability, or the probability of n or fewer no-hitters; p49 is the predicted number of seasons out of 49 (1961-2009) that we would expect to have n no-hitters; obs is the observed number of seasons with n no-hitters; cp49 is the predicted number of seasons with n or fewer no-hitters; and cobs is the observed number of seasons with n or fewer no-hitters.
Above is the distribution. p is the probability of exactly n no-hitters being thrown in a single season of 4112 games; cdf is the cumulative probability, or the probability of n or fewer no-hitters; p49 is the predicted number of seasons out of 49 (1961-2009) that we would expect to have n no-hitters; obs is the observed number of seasons with n no-hitters; cp49 is the predicted number of seasons with n or fewer no-hitters; and cobs is the observed number of seasons with n or fewer no-hitters.
It’s clear that 4 or even 5 no-hitters is a perfectly reasonable number to expect.
| 2.448760831 |
June 15 Wins Above Expectation June 16, 2010
Posted by tomflesher in Baseball.Tags: Angels, Baseball, Rays, Tigers, wins above expectation
add a comment
Wins Above Expectation are a statistic determined using team wins and the Pythagorean expectation, which is in turn determined using runs scored by and against each team. The Pythagorean expectation is the proportion of runs scored squared to runs scored squared plus runs against squared. It’s interpreted as an expected winning percentage.
Wins Above Expectation (WAE) is then the difference between Wins and Expected Wins, which are simply the Pythagorean Expectation multiplied by Games played. It’s a useful measure because it can be interpreted as wins that are due to efficiency (in economic terms) or, more simply, play that’s some combination of smart, clutch, and non-wasteful. It rewards winning close games and penalizes teams that win lots of laughers but lose close games, since the big wins predict more games will be won when all those runs are spent winning only one game.
Using Baseball-Reference.com, I crunched the numbers for AL teams up to June 15. As usual, the Los Angeles Angels of Anaheim lead the league in WAE with 3.68, with Detroit’s 2.39 a close second, but the Tampa Bay Rays are a surprising last with -1.96 WAE. Obviously, this early in the season it’s too soon to conclude anything based on this, but the complete data is behind the cut. (more…)
So why doesn't Nick Swisher pitch every night? April 15, 2009
Posted by tomflesher in Baseball.Tags: Cardinals, Cody Ransom, comparative advantage, Economics haiku, emergency relievers, Gabe Kapler, Joe Girardi, market for pitchers, Moneyball alumni, Nick Swisher, position players pitching, Rays, Scott Spiezio, Wade Boggs, Yankees
add a comment
Nick Swisher pitched for the first time in the major leagues on Monday night during the Yankees’ 15-5 loss to the Tampa Bay Rays. As you can see from the box score, Swish pitched pretty well. In fact, in 22 pitches, he gave up only one hit and one walk, threw 12 strikes, and struck out a major-league batter (left-fielder Gabe Kapler). So, will Yankees manager Joe Girardi tap him in relief again soon?
No, of course not. Find out why behind the cut.
Statistical evidence that the Rays are outclassed. October 27, 2008
Posted by tomflesher in Baseball.Tags: Baseball, Phillies, Rays
1 comment so far
The series thus far.
Q.E.D.
Poor Kazmir. October 17, 2008
Posted by tomflesher in Baseball.Tags: ALCS, Baseball, Cy Young, John Smoltz, Mike Mussina, Rays, Red Sox, Scott Kazmir, weird lines
add a comment
Last night, Scott Kazmir pitched 6 scoreless innings in ALCS game 5, giving up 2 hits and 3 walks but striking out 7 batters. He totalled up to a game score of 72 points. His bullpen then proceeded to give up 8 runs, allowing the Red Sox to come back and win the game (thus extending the series to game 5).
Has Scotty suffered the greatest postseason indignity ever? Nope. Not even close. That honor belongs to Mike Mussina of the 1997 Orioles.
Wins Above Expectation (with a side of run differential) September 1, 2008
Posted by tomflesher in Baseball.Tags: Angels, Baseball, Blue Jays, Rays, Research, sabermetrics
2 comments
In continuing my thoughts about the Pythagorean Expectation from about a week ago, I took a look at the MLB standings for the period ending August 31, 2008. I played with the stats a little bit, since I haven’t really thought through the basis for most of them.
Today’s project: find Pythagorean expectations for each team, then find the difference between the actual and expected win percentages (“pythagorean difference”). Apply the pythagorean difference to the total number of games played to determine a team’s Wins Above Expectation by multiplying the total number of games by the pythagorean difference.
Practical application: none.
Discussion and numbers behind the cut.
