Why isn’t baseball’s free agent market clearing? February 21, 2019
Posted by tomflesher in Baseball, Economics.Tags: Baseball, economics, microeconomics, sabermetrics, sports economics, winner's curse
add a comment
There’s been some discussion of the free agent market in baseball and its alleged inefficiency – that players like Manny Machado don’t sign until February and Bryce Harper is still unsigned, for example. Adam Wainwright, for example, has threatened a strike over free agency.
Certainly, there are many factors in play. However, the fact that there are stars who aren’t being picked up doesn’t mean that there’s anything nefarious afoot. Brad Brach, who signed with the Cubs on February 11, has complained about the teams’ use of algorithms to value players:
Brad Brach on his free-agency experience: “We talked to certain teams and they told us that, ‘We have an algorithm and here’s where you fall.’ … It’s just kind of weird that all offers are the same, they come around the same time. Everybody tells you there’s an algorithm.”
— Jordan Bastian (@MLBastian) February 15, 2019
https://platform.twitter.com/widgets.js
Let’s take that at face value and build a model of algorithms and noise. (It seems that Brach is implying collusion by teams, but in a future post I’ll discuss why I don’t think that’s likely.)
First, the simplifying assumptions:
- Players have an accurate valuation of their own talent levels (This is difficult to justify because players have an incentive to overvalue themselves, but the conclusions would not change qualitatively by relaxing this assumption)
- Teams have a noisy valuation of players based on the players’ talent levels (This is essentially the face value Brach’s claim: that teams use ‘algorithms’ based on player talent.)
- There are two teams with similar noise levels. (Modeling different forms of bias, or different preferences by teams, would probably not change the outcome very much, but would affect the distribution of players. Meanwhile, the market for some players is fairly large, but for many it’s very small, especially as prices rise.)
- All contracts are for one year. (This avoids the trouble of modeling players’ intertemporal rates of substitution, but a future version of this model may include preferences about both pay and number of years.)
- If a player is offered a contract that he thinks accurately reflects or overpays him, he signs with the team that offers him the bigger contract.
Poorly-constructed R code for a simulated free agent season:
data<-matrix(1:5000,nrow=1000,ncol=5)
for (i in c(1:1000)){data[i,1] <- runif(1)
data[i,2] <- data[i,1]+rnorm(1,mean=0,sd=.05)
data[i,3] <- data[i,1]+rnorm(1,mean=0,sd=.1)
data[i,4] <- max(data[i,2],data[i,3])
data[i,5] <- if(data[i,4]>=data[i,1]) data[i,5]=1 else data[i,5]=0}
Basically, generate a vector of random player talent levels; team 1 accurately values players with a standard deviation of .05, while team 2 accurately values them with a standard deviation of .1. 1000 players go on the market. Outcome:
| V1 | V2 | V3 | V4 | V5 |
| Min. :0.0008885 | Min. : -0.1324 | Min. : -0.2024 | Min. : -0.1324 | Min. :0.000 |
| 1st Qu.:0.2613380 | 1st Qu.: 0.2621 | 1st Qu.: 0.2608 | 1st Qu.: 0.3012 | 1st Qu.:1.000 |
| Median :0.4984726 | Median : 0.4968 | Median : 0.5133 | Median : 0.5511 | Median :1.000 |
| Mean :0.4997539 | Mean : 0.4987 | Mean : 0.5087 | Mean : 0.548 | Mean :0.754 |
| 3rd Qu.:0.7425434 | 3rd Qu.: 0.743 | 3rd Qu.: 0.7566 | 3rd Qu.: 0.7912 | 3rd Qu.:1.000 |
| Max. :0.9995596 | Max. : 1.1115 | Max. : 1.2508 | Max. : 1.2508 | Max. :1.000 |
That’s right – only 754 of the 1000 players signed. (In multiple simulations, the signing rate hovers around 75%. This makes sense theoretically, since valuations are independent: half the players will be undervalued by each team so 1/4 will be undervalued by both teams.)
Interestingly, player 973 is unsigned:
[973,] 0.9683805341 0.9472948838 0.874961530 0.9472948838 0
He evaluated himself at below the 97th percentile, but got unlucky in that both teams evaluated him below that: team 1 would offer him a 95th percentile contract and team 2 would rank him even further down.
Meanwhile, player 25 gets lucky:
[25,] 0.0109281745 0.0236191242 0.089982324 0.0899823237 1
Despite being in the 1st percentile, both teams accidentally overvalue him, and his contract ends up being suited to a player with nearly 9 times his value. (For the phenomenon where competition leads reliably to overpayment, see “winner’s curse.”)
We’re going to see both of these types of errors in any market where there’s a subjective evaluation of players. Particularly if the teams are using algorithmic valuations, much of the information they’re based on is going to be publicly available; even if teams weight it differently, efficient algorithms are likely to produce similar results.
Back when it was hard to hit 55… July 8, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, home runs, R, regression, sabermetrics, Stuff Keith Hernandez Says, talent pool dilution, Willie Mays, Year of the Pitcher
add a comment
Last night was one of those classic Keith Hernandez moments where he started talking and then stopped abruptly, which I always like to assume is because the guys in the truck are telling him to shut the hell up. He was talking about Willie Mays for some reason, and said that Mays hit 55 home runs “back when it was hard to hit 55.” Keith coyly said that, while it was easy for a while, it was “getting hard again,” at which point he abruptly stopped talking.
Keith’s unusual candor about drug use and Mays’ career best of 52 home runs aside, this pinged my “Stuff Keith Hernandez Says” meter. After accounting for any time trend and other factors that might explain home run hitting, is there an upward trend? If so, is there a pattern to the remaining home runs?
The first step is to examine the data to see if there appears to be any trend. Just looking at it, there appears to be a messy U shape with a minimum around t=20, which indicates a quadratic trend. That means I want to include a term for time and a term for time squared.
Using the per-game averages for home runs from 1955 to 2009, I detrended the data using t=1 in 1955. I also had to correct for the effect of the designated hitter. That gives us an equation of the form
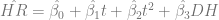
The results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.957 | 0.0328 | 29.189 | 0.0001 | 0.9999 |
| t | -0.0188 | 0.0028 | -6.738 | 0.0001 | 0.9999 |
| tsq | 0.0004 | 0.00005 | 8.599 | 0.0001 | 0.9999 |
| DH | 0.0911 | 0.0246 | 3.706 | 0.0003 | 0.9997 |
We can see that there’s an upward quadratic trend in predicted home runs that together with the DH rule account for about 56% of the variation in the number of home runs per game in a season (
Then, I needed to look at the difference between the predicted number of home runs per game and the actual number of home runs per game, which is accessible by subtracting
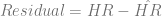
This represents the “abnormal” number of home runs per year. The question then becomes, “Is there a patt ern to the number of abnormal home runs?” There are two ways to answer this. The first way is to look at the abnormal home runs. Up until about t=40 (the mid-1990s), the abnormal home runs are pretty much scattershot above and below 0. However, at t=40, the residual jumps up for both leagues and then begins a downward trend. It’s not clear what the cause of this is, but the knee-jerk reaction is that there might be a drug use effect. On the other hand, there are a couple of other explanations.
ern to the number of abnormal home runs?” There are two ways to answer this. The first way is to look at the abnormal home runs. Up until about t=40 (the mid-1990s), the abnormal home runs are pretty much scattershot above and below 0. However, at t=40, the residual jumps up for both leagues and then begins a downward trend. It’s not clear what the cause of this is, but the knee-jerk reaction is that there might be a drug use effect. On the other hand, there are a couple of other explanations.
The most obvious is a boring old expansion effect. In 1993, the National League added two teams (the Marlins and the Rockies), and in 1998 each league added a team (the AL’s Rays and the NL’s Diamondbacks). Talent pool dilution has shown up in our discussion of hit batsmen, and I believe that it can be a real effect. It would be mitigated over time, however, by the establishment and development of farm systems, in particular strong systems like the one that’s producing good, cheap talent for the Rays.
Pinch Hitters from the Bullpen July 6, 2010
Posted by tomflesher in Baseball, Economics.Tags: binomial distribution, bullpen, Carlos Zambrano, Livan Hernandez, margin of error, Micah Owings, pinch hitter, sabermetrics
add a comment
Occasionally, a solid two-way player shows up in the majors. Carlos Zambrano is known as a solid hitter with a great arm (despite the occasional meltdown), and Micah Owings is the rare pitcher used as a pinch hitter. Even Livan Hernandez has 15 pinch-hit plate appearances (with 2 sacrifice bunts, 6 strikeouts, and a .077 average and .077 OBP, compared with a lifetime .227 average and .237 OBP).
Like Hernandez, Zambrano has a very different batting line as a pinch hitter than as a pitcher. In 24 plate appearances as a pinch hitter, Big Z is hitting only .087 with a .087 OBP, compared to his .243/.249 line when hitting as a pitcher. Since we see the same effect for both of these pitchers, it seems like there’s some sort of difference in hitting as a pinch hitter that causes the pitchers to be less mentally prepared. Of course, these numbers come from a very small sample.
On the other hand, Micah Owings hits .307/.331 as a pitcher, and a quite similar .250/.298 as a pinch hitter. What’s the difference? Owings has almost double Zambrano’s plate appearances as a pinch hitter with 47. That seems to show that maybe Owings’ larger sample size is what causes the similarity. How can this be tested rigorously?
As we did with Kevin Youkilis and his title of Greek God of Take Your Base, we can use the binomial distribution to see if it’s reasonable for Owings, Hernandez and Zambrano to hit so differently as pinch hitters. To figure out whether it’s reasonable or not, let’s limit our inquiry to OBP just because it’s a more inclusive measure and then assume that the batting average as a pitcher (i.e. the one with a larger sample size) is the pitcher’s “true” batting average and use that to represent the probability of getting on base. Each plate appearance is a Bernoulli trial with a binary outcome – we’ll call it a success if the player gets on base and a failure otherwise.
Under the binomial distribution, the probability of a player with OBP p getting on base k times in n plate appearances is:
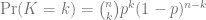
with
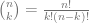
We’ll also need the margin of error for proportions. If p = OBP as pitcher, and we assume a t-distribution with over 100 plate appearances (i.e. degrees of freedom), then the margin of error is:
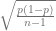
so that 95% of the time we’d expect the pinch hitting OBP to lie within

with
We’ll also need the margin of error for proportions. If p = OBP as pitcher, and we assume a t-distribution with over 100 plate appearances (i.e. degrees of freedom), then the margin of error is:
so that 95% of the time we’d expect the pinch hitting OBP to lie within
Let’s start with Owings. He has an OBP of .331 as a pitcher in 151 plate appearances, so the probability of having at most 14 times on base in 47 plate appearances is .3778. In other words, about 38% of the time, we’d expect a random string of 47 plate appearances to have 14 or fewer times on base. His 95% confidence interval is .254 to .408, so his .298 OBP as a pinch hitter is certainly statistically credible.
Owings is special, though. Hernandez, for example, has 994 plate appearances as a pitcher and a .237 OBP, with only one time on base in 15 plate appearances. It’s a very small sample, but the binomial distribution predicts he would have at most one time on base only about 9.8% of the time. His confidence interval is .210 to .264, which means that it’s very unlikely that he’d end up with an OBP of .077 unless there is some relevant difference between hitting as a pitcher and hitting as a pinch hitter.
Zambrano’s interval breaks down, too. He has 601 plate appearances as a pitcher with a .249 OBP, but an anemic .087 OBP (two hits) in 24 plate appearances as a pinch hitter. We’d expect 2 or fewer hits only 4% of the time, and 95% of the time we’d expect Big Z to hit between .214 and .284.
As a result, we can make two determinations.
- Zambrano and Hernandez are hitting considerably below expectations as pinch hitters. It’s likely, though not proven, that this is a pattern among most pitchers.
- Micah Owings is a statistical outlier from the pattern. It’s not clear why.
Manny’s First 27 Games (or, the Marginal Product of Drug Use) June 4, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, Dodgers, economics, Manny Ramirez, performance-enhancing drugs, sabermetrics, sports economics, statistics, suspension
add a comment
Last year, Manny Ramirez was suspended for 50 games on May 6. The suspension came after his 27th game of the season. On May 25th of this year, Manny played his 27th game of 2010. That means we can take a look at the first 27 games of each season, when he was using performance-enhancing drugs (in 2009) and when he wasn’t (presumably, this year). The differential line is behind the cut.
Quickie: Dallas Braden's Perfect Game May 11, 2010
Posted by tomflesher in Baseball.Tags: Baseball, Braden's perfect game, Buehrle's perfect game, Dallas Braden, Oakland As, probability, sabermetrics, Tampa Bay Rays
add a comment
Dallas Braden of the Oakland As pitched a perfect game Sunday, on Mother’s Day. Under the methods discussed last year after Buehrle’s perfect game, Braden – who’s been active for four seasons – has an OBP-against of .328. That means he has a probability for any given plate appearance of .672 of the batter not reaching base.
Since he sat down 27 batters consecutively, the probability of that event happening is (.672)27, or .0000218; equivalently, given his current stats, a bit over 2 in every 100,000 games that Braden pitches should be perfect games.
Over the same period (2007-2010), the American League OBP has hovered between .331 (this year) and .338 (2007). .336 was the mode (2008, 2009), so I’ll use it to estimate that the chance for a perfect game facing the league average team would be (.664)27, or .0000157, or equivalently about 1.5 out of every 100,000 games should be a perfect game.As you can see, it’s more likely for Braden than the average pitcher, but not by much.
Nice job, Dallas!
As a side note, the Tampa Bay Rays were the victim of BOTH perfect games. Their team OBP was .343 in 2009, with a probability not to get on base of .657, meaning that the probability of getting 27 batters seated consecutively is about 1.2 in 100,000. Since many other teams have lower team OBPs, it’s very surprising that the Rays were the victims of both games.
Cy Young gives me a headache. January 15, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, Bill James, Cy Young predictor, economics, Eric Gagne, linear regression, R, Rob Neyer, sabermetrics, Tim Lincecum, Weighted saves, Weighted shutouts
add a comment
As usual, I’ve started my yearly struggle against a Cy Young predictor. Bill James and Rob Neyer’s predictor (which I’ve preserved for posterity here) did a pretty poor job this year, having predicted the wrong winner in both leagues and even getting the order very wrong compared to the actual results. Inside, I’d like to share some of my pain, since I can’t seem to do much better.
Silly bean counters September 7, 2008
Posted by tomflesher in Baseball.Tags: Baseball, economics, Research, sabermetrics
add a comment
I came across the Beane Count, invented by ESPN.com’s Rob Neyer, by accident. My first thought: “That’s crap. Just summing ranks doesn’t accomplish anything.” My second thought: “How can I prove this?”
My third through nth thoughts involved my standard method of creating a needlessly complex spreadsheet using data culled from ESPN.com. The results were quite surprising.
Wins Above Expectation (with a side of run differential) September 1, 2008
Posted by tomflesher in Baseball.Tags: Angels, Baseball, Blue Jays, Rays, Research, sabermetrics
2 comments
In continuing my thoughts about the Pythagorean Expectation from about a week ago, I took a look at the MLB standings for the period ending August 31, 2008. I played with the stats a little bit, since I haven’t really thought through the basis for most of them.
Today’s project: find Pythagorean expectations for each team, then find the difference between the actual and expected win percentages (“pythagorean difference”). Apply the pythagorean difference to the total number of games played to determine a team’s Wins Above Expectation by multiplying the total number of games by the pythagorean difference.
Practical application: none.
Discussion and numbers behind the cut.
Things I spend a lot of time thinking about August 3, 2008
Posted by tomflesher in Uncategorized.Tags: beer, brewing, economics, Mets, Research, sabermetrics, Yankees
add a comment
Baseball generally, the New York teams specifically, applied economics, sabermetrics (wait, those two are the same thing), Canada, Canadian politics, rational choice theory in professional sports, homebrewing, the hop shortage, torbie cats named Samantha, US politics, Brewery Ommegang.
