Why isn’t baseball’s free agent market clearing? February 21, 2019
Posted by tomflesher in Baseball, Economics.Tags: Baseball, economics, microeconomics, sabermetrics, sports economics, winner's curse
add a comment
There’s been some discussion of the free agent market in baseball and its alleged inefficiency – that players like Manny Machado don’t sign until February and Bryce Harper is still unsigned, for example. Adam Wainwright, for example, has threatened a strike over free agency.
Certainly, there are many factors in play. However, the fact that there are stars who aren’t being picked up doesn’t mean that there’s anything nefarious afoot. Brad Brach, who signed with the Cubs on February 11, has complained about the teams’ use of algorithms to value players:
Brad Brach on his free-agency experience: “We talked to certain teams and they told us that, ‘We have an algorithm and here’s where you fall.’ … It’s just kind of weird that all offers are the same, they come around the same time. Everybody tells you there’s an algorithm.”
— Jordan Bastian (@MLBastian) February 15, 2019
https://platform.twitter.com/widgets.js
Let’s take that at face value and build a model of algorithms and noise. (It seems that Brach is implying collusion by teams, but in a future post I’ll discuss why I don’t think that’s likely.)
First, the simplifying assumptions:
- Players have an accurate valuation of their own talent levels (This is difficult to justify because players have an incentive to overvalue themselves, but the conclusions would not change qualitatively by relaxing this assumption)
- Teams have a noisy valuation of players based on the players’ talent levels (This is essentially the face value Brach’s claim: that teams use ‘algorithms’ based on player talent.)
- There are two teams with similar noise levels. (Modeling different forms of bias, or different preferences by teams, would probably not change the outcome very much, but would affect the distribution of players. Meanwhile, the market for some players is fairly large, but for many it’s very small, especially as prices rise.)
- All contracts are for one year. (This avoids the trouble of modeling players’ intertemporal rates of substitution, but a future version of this model may include preferences about both pay and number of years.)
- If a player is offered a contract that he thinks accurately reflects or overpays him, he signs with the team that offers him the bigger contract.
Poorly-constructed R code for a simulated free agent season:
data<-matrix(1:5000,nrow=1000,ncol=5)
for (i in c(1:1000)){data[i,1] <- runif(1)
data[i,2] <- data[i,1]+rnorm(1,mean=0,sd=.05)
data[i,3] <- data[i,1]+rnorm(1,mean=0,sd=.1)
data[i,4] <- max(data[i,2],data[i,3])
data[i,5] <- if(data[i,4]>=data[i,1]) data[i,5]=1 else data[i,5]=0}
Basically, generate a vector of random player talent levels; team 1 accurately values players with a standard deviation of .05, while team 2 accurately values them with a standard deviation of .1. 1000 players go on the market. Outcome:
| V1 | V2 | V3 | V4 | V5 |
| Min. :0.0008885 | Min. : -0.1324 | Min. : -0.2024 | Min. : -0.1324 | Min. :0.000 |
| 1st Qu.:0.2613380 | 1st Qu.: 0.2621 | 1st Qu.: 0.2608 | 1st Qu.: 0.3012 | 1st Qu.:1.000 |
| Median :0.4984726 | Median : 0.4968 | Median : 0.5133 | Median : 0.5511 | Median :1.000 |
| Mean :0.4997539 | Mean : 0.4987 | Mean : 0.5087 | Mean : 0.548 | Mean :0.754 |
| 3rd Qu.:0.7425434 | 3rd Qu.: 0.743 | 3rd Qu.: 0.7566 | 3rd Qu.: 0.7912 | 3rd Qu.:1.000 |
| Max. :0.9995596 | Max. : 1.1115 | Max. : 1.2508 | Max. : 1.2508 | Max. :1.000 |
That’s right – only 754 of the 1000 players signed. (In multiple simulations, the signing rate hovers around 75%. This makes sense theoretically, since valuations are independent: half the players will be undervalued by each team so 1/4 will be undervalued by both teams.)
Interestingly, player 973 is unsigned:
[973,] 0.9683805341 0.9472948838 0.874961530 0.9472948838 0
He evaluated himself at below the 97th percentile, but got unlucky in that both teams evaluated him below that: team 1 would offer him a 95th percentile contract and team 2 would rank him even further down.
Meanwhile, player 25 gets lucky:
[25,] 0.0109281745 0.0236191242 0.089982324 0.0899823237 1
Despite being in the 1st percentile, both teams accidentally overvalue him, and his contract ends up being suited to a player with nearly 9 times his value. (For the phenomenon where competition leads reliably to overpayment, see “winner’s curse.”)
We’re going to see both of these types of errors in any market where there’s a subjective evaluation of players. Particularly if the teams are using algorithmic valuations, much of the information they’re based on is going to be publicly available; even if teams weight it differently, efficient algorithms are likely to produce similar results.
Modeling Run Production June 19, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, economics, regression, run production, sports economics
add a comment
A baseball team can be thought of as a factory which uses a single crew to operate two machines. The first machine produces runs while the team bats, and the second machine produces outs while the team is on fields. This is a somewhat abstract way to look at the process of winning games, because ordinarily machines have a fixed input and a fixed output. In a box factory, the input comprises man-hours and corrugated board, and the output is a finished box. Here, the input isn’t as well-defined.
Runs are a function of total bases, certainly, but total bases are functions of things like hits, home runs, and walks. Basically, runs are a function of getting on base and of advancing people who are already on base. Obviously, the best measure of getting on base is On-Base Percentage, and Slugging Average (expected number of bases per at-bat) is a good measure of advancement.
OBP wraps up a lot of things – walks, hits, and hit-by-pitch appearances – and SLG corrects for the greater effects of doubles, triples, and home runs. That doesn’t account for a few other things, though, like stolen bases, sacrifice flies, and sacrifice hits. It also doesn’t reflect batter ability directly, but that’s okay – the stats we have should represent batter ability since the defensive side is trying to prevent run production. The model might look something like this, then:

This is the simplest model we can start with – each factor contributes a discrete number of runs. If we need to (and we probably will), we can add terms to capture concavity of the marginal effect of different stats, or (more likely) an interaction term for SLG and, say, SB, so that a stolen base is worth more on a team where you’re more likely to be brought home by a batter because he’s more likely to give you extra bases. As it is, however, we can test this model with linear regression. The details of it are behind the cut. (more…)
Trends in DH use June 11, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, designated hitter, economics, Interleague play, Mets, regression, sports economics, Stuff Keith Hernandez Says
add a comment
Last night, Keith Hernandez was talking about how the Mets are scheduled to play in American League parks starting, well, today. He pointed out that the Mets will be in a bit of a pickle because they aren’t built, as AL teams are, to carry one big hitter to be the full-time DH. Instead, an NL team will be forced to spread the wealth among lighter hitters who are carried for their defensive acumen as well as their offensive prowess. Keith then corrected himself and said that AL managers are using the DH differently – to rest individual players instead of having an everyday DH.
That pinged my “Stuff Keith Hernandez says” meter, and so I decided to crunch some numbers and see if that’s true. I interpreted Keith’s statement as implying that the number of designated hitters should be increasing, since managers are moving away from an everyday DH and toward spreading the DH assignments around a bit more. The crunching also needs to account for interleague play, which should obviously increase the number of DHes. So, after controlling for interleague play, does DH use show an increasing trend with time?
Is Hatred-Based Investment Rational? June 9, 2010
Posted by tomflesher in Economics, US Politics.Tags: economics, finance, investment, Scott Adams, utility hedging, Wall Street Journal
add a comment
Scott Adams (of Dilbert fame) has an essay in the Wall Street Journal about investing in companies you hate. His reasoning is that “the company is so powerful it can make you balance your wallet on your nose while you beg for their product.”
Is hatred-based investing rational? Making the usual assumptions (people are rational utility maximizers, etc), and assuming that you gain some utility from seeing a company you hate losing money, and that you lose a commensurate amount of utility from seeing that company make money, then it’s absolutely rational under certain circumstances. Mainly, it would serve as a hedge strategy against emotional distress. In Adams’ example, he’s talking about BP and their recent oil spill. Owning BP provides a hedge against the disutility of watching BP potentially recover and begin to profit again – you get paid an amount that should offset some of your lost utility. Conversely, if you lose money, at least your money loss is offset by a gain in utility.
Obviously, it’s not something to do with all of your money. The optimal hedge ratio will also vary consumer-by-consumer.
Manny’s First 27 Games (or, the Marginal Product of Drug Use) June 4, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, Dodgers, economics, Manny Ramirez, performance-enhancing drugs, sabermetrics, sports economics, statistics, suspension
add a comment
Last year, Manny Ramirez was suspended for 50 games on May 6. The suspension came after his 27th game of the season. On May 25th of this year, Manny played his 27th game of 2010. That means we can take a look at the first 27 games of each season, when he was using performance-enhancing drugs (in 2009) and when he wasn’t (presumably, this year). The differential line is behind the cut.
Does the DH Rule Cause Batters to be Hit? June 2, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, designated hitter, economics, hit by pitch, Kevin Youkilis, regression, sports economics
add a comment
In an earlier post, I crunched some numbers on the Designated Hitter rule and came to the conclusion that the DH adds about .3 extra trips to first base per game after accounting for trend. I’m going to play around with another stat that a lot of people seem to think should be affected indirectly by the DH rule.
The Conventional Wisdom™ is that the DH should increase hit batsman. The argument is that pitchers don’t bear the costs of hitting a batter with a pitch because they don’t bat, so they’ll be less careful to avoid hitting a batter or more likely to plunk a batter out of malice. Do the numbers bear that out?
Addendum on Pythagorean Expectation May 20, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, economics, Pythagorean expectation, statistics
1 comment so far
I noted below that the sample size of 13 games is too small to make a determination as to whether the proportions of conditions expected to predict the winning team – the home team, the team with the higher Pythagorean expectation, the team with more runs scored, and the team with the higher run differential – is significantly different from chance. If chance were the only determinant of the winner, then we would expect each proportion to be .5, since you’d expect a randomly-selected home team to win half the games, a randomly-selected team with higher run differential to win half the games, and so on.
Making the standard statistical assumptions, the margin of error using proportions is 

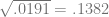
For the simple measure of more runs, the proportion was .31, meaning that the margin of error is 
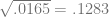
Cy Young gives me a headache. January 15, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, Bill James, Cy Young predictor, economics, Eric Gagne, linear regression, R, Rob Neyer, sabermetrics, Tim Lincecum, Weighted saves, Weighted shutouts
add a comment
As usual, I’ve started my yearly struggle against a Cy Young predictor. Bill James and Rob Neyer’s predictor (which I’ve preserved for posterity here) did a pretty poor job this year, having predicted the wrong winner in both leagues and even getting the order very wrong compared to the actual results. Inside, I’d like to share some of my pain, since I can’t seem to do much better.
The Misery Index April 2, 2009
Posted by tomflesher in Academia, Economics, US Politics.Tags: economics, Economics haiku, macroeconomics, Misery Index, research project ideas
add a comment
The Misery Index is a measure of national economic health derived by adding the unemployment rate to the rate of inflation. It was famously used by Jimmy Carter to declare that Gerald Ford, under whom the rate had risen to 12.5%, had no right to run the country, and then by Ronald Reagan to declare that Carter was unfit for the presidency after it rose to over 20%. (It’s available in real time at MiseryIndex.us.) (more…)

{kind=link}