Home Runs Per Game: A bit more in-depth December 23, 2011
Posted by tomflesher in Baseball, Economics.Tags: AR, autoregression, baseball-reference.com, home runs, home runs per plate appearance, linear regression, talent pool dilution
add a comment
I know I’ve done this one before, but in my defense, it was a really bad model.
I made some odd choices in modeling run production in that post. The first big questionable choice was to detrend according to raw time. That might make sense starting with a brand-new league, where we’d expect players to be of low quality and asymptotically approach a true level of production – a quadratic trend would be an acceptable model of dynamics in that case. That’s not a sensible way to model the major leagues, though; even though there’s a case to be made that players being in better physical condition will lead to better production, there’s no theoretical reason to believe that home run production will grow year over year.
So, let’s cut to the chase: I’m trying to capture a few different effects, and so I want to start by running a linear regression of home runs on a couple of controlling factors. Things I want to capture in the model:
- The DH. This should have a positive effect on home runs per game.
- Talent pool dilution. There are competing effects – more batters should mean that the best batters are getting fewer plate appearances, as a percentage of the total, but at the same time, more pitchers should mean that the best pitchers are facing fewer batters as a percentage of the total. I’m including three variables: one for the number of batters and one for the number of pitchers, to capture those effects individually, and one for the number of teams in the league. (All those variables are in natural logarithm form, so the interpretation will be that a 1% change in the number of batters, pitchers, or teams will have an effect on home runs.) The batting effect should be negative (more batters lead to fewer home runs); the pitching effect should be positive (more pitchers mean worse pitchers, leading to more home runs); the team effect could go either way, depending on the relative strengths of the effects.
- Trends in strategy and technology. I can’t theoretically justify a pure time trend, but I also can’t leave out trends entirely. Training has improved. Different training regimens become popular or fade away, and some strategies are much different than in previous years. I’ll use an autoregressive process to model these.
My dependent variable is going to be home runs per plate appearance. I chose HR/PA for two reasons:
- I’m using Baseball Reference’s AL and NL Batting Encyclopedias, which give per-game averages; HR per game/PA per game will wash out the per-game adjustments.
- League HR/PA should show talent pool dilution as noted above – the best hitters get the same plate appearances but their plate appearances will make up a smaller proportion of the total. I’m using the period from 1955 to 2010.
After dividing home runs per game by plate appearances per game, I used R to estimate an autoregressive model of home runs per plate appearance. That measures whether a year with lots of home runs is followed by a year with lots of home runs, whether it’s the reverse, or whether there’s no real connection between two consecutive years. My model took the last three years into account:

Since the model doesn’t fit perfectly, there will be an “error” term, 
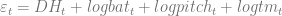
The results:

The DH and batter effects aren’t statistically different from zero, surprisingly; the pitching effect and the team effect are both significant at the 95% level. Interestingly, the team effect and the pitching effect have opposite signs, meaning that there’s some factor in increasing the number of teams that doesn’t relate purely to pitching or batting talent pool dilution.
For the record, fitted values of innovations correlate fairly highly with HR/PA: the correlation is about .70, despite a pretty pathetic R-squared of .08.
Back when it was hard to hit 55… July 8, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, home runs, R, regression, sabermetrics, Stuff Keith Hernandez Says, talent pool dilution, Willie Mays, Year of the Pitcher
add a comment
Last night was one of those classic Keith Hernandez moments where he started talking and then stopped abruptly, which I always like to assume is because the guys in the truck are telling him to shut the hell up. He was talking about Willie Mays for some reason, and said that Mays hit 55 home runs “back when it was hard to hit 55.” Keith coyly said that, while it was easy for a while, it was “getting hard again,” at which point he abruptly stopped talking.
Keith’s unusual candor about drug use and Mays’ career best of 52 home runs aside, this pinged my “Stuff Keith Hernandez Says” meter. After accounting for any time trend and other factors that might explain home run hitting, is there an upward trend? If so, is there a pattern to the remaining home runs?
The first step is to examine the data to see if there appears to be any trend. Just looking at it, there appears to be a messy U shape with a minimum around t=20, which indicates a quadratic trend. That means I want to include a term for time and a term for time squared.
Using the per-game averages for home runs from 1955 to 2009, I detrended the data using t=1 in 1955. I also had to correct for the effect of the designated hitter. That gives us an equation of the form
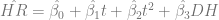
The results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.957 | 0.0328 | 29.189 | 0.0001 | 0.9999 |
| t | -0.0188 | 0.0028 | -6.738 | 0.0001 | 0.9999 |
| tsq | 0.0004 | 0.00005 | 8.599 | 0.0001 | 0.9999 |
| DH | 0.0911 | 0.0246 | 3.706 | 0.0003 | 0.9997 |
We can see that there’s an upward quadratic trend in predicted home runs that together with the DH rule account for about 56% of the variation in the number of home runs per game in a season (
Then, I needed to look at the difference between the predicted number of home runs per game and the actual number of home runs per game, which is accessible by subtracting
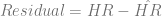
This represents the “abnormal” number of home runs per year. The question then becomes, “Is there a patt ern to the number of abnormal home runs?” There are two ways to answer this. The first way is to look at the abnormal home runs. Up until about t=40 (the mid-1990s), the abnormal home runs are pretty much scattershot above and below 0. However, at t=40, the residual jumps up for both leagues and then begins a downward trend. It’s not clear what the cause of this is, but the knee-jerk reaction is that there might be a drug use effect. On the other hand, there are a couple of other explanations.
ern to the number of abnormal home runs?” There are two ways to answer this. The first way is to look at the abnormal home runs. Up until about t=40 (the mid-1990s), the abnormal home runs are pretty much scattershot above and below 0. However, at t=40, the residual jumps up for both leagues and then begins a downward trend. It’s not clear what the cause of this is, but the knee-jerk reaction is that there might be a drug use effect. On the other hand, there are a couple of other explanations.
The most obvious is a boring old expansion effect. In 1993, the National League added two teams (the Marlins and the Rockies), and in 1998 each league added a team (the AL’s Rays and the NL’s Diamondbacks). Talent pool dilution has shown up in our discussion of hit batsmen, and I believe that it can be a real effect. It would be mitigated over time, however, by the establishment and development of farm systems, in particular strong systems like the one that’s producing good, cheap talent for the Rays.
