Micah Owings and Cobb-Douglas Production July 22, 2010
Posted by tomflesher in Baseball, Economics.Tags: Brooks Kieschnick, Cobb-Douglas function, David Ortiz, Micah Owings, Reds, run production
1 comment so far
Micah Owings, who is one of the best two-way players in baseball since Brooks Kieschnick, was sent down to the minors by the Cincinnati Reds yesterday. As big a fan as I am of Micah (really, look at the blog), I think this was probably the right decision.
Owings was being used as a long reliever. For a big-hitting pitcher like Micah, that’s death to begin with. Relievers need to be available to pitch, so the Reds couldn’t get their money’s worth from Owings as a pinch hitter, since he wouldn’t be available to re-enter the game as a pitcher unless they used him immediately. They also weren’t getting their money’s worth as a pitcher, since, as Cincinnati.com notes, the Reds’ starting pitching was doing very well and so long relief wasn’t being used very often.
Letting Owings start in AAA will give him the best possible outcome – he’ll have regular opportunities to pitch, so he won’t rust, and he’ll get to bat at least some of the time. Owings needs to be cultivated as a batter because that’s where his comparative advantage is. I doubt he’ll ever be at the top of the rotation, but he could be a competent fifth starter. If he pitches often enough to get there, he’ll add significant value to the team in terms of his OBP above the expected pitcher. He’ll get on base more, so he’ll both advance runners and avoid making an out.
A baseball player is a factory for producing run differential. He does so using two inputs: defensive ability (pitching and fielding) and offensive ability (batting). In the National League, if a player can’t hit at all, he’s likely to produce very little in the way of run differential, but at the same time, if he’s a liability on defense, he’s not likely to be very useful either. Defense produces marginal runs by preventing opposing runs from scoring, and offense produces marginal runs by scoring runs. Having either one set to zero (in the case of a pitcher who can’t hit at all) or a negative value (an actively bad pitcher) would negatively affect the player’s run production. This is similar to a factory situation where labor and equipment are used to produce goods, and that situation is usually modeled using a Cobb-Douglas production function:
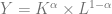
with Y = production, z = a productivity constant, K = equipment and technology, L = labor input, and 
In general, production of run differential could be modeled using the same method. For example:

where P = pitching contribution, F = fielding contribution, B = batting contribution, and 
The upshot of this method of modeling production is that it shows Owings can make up for being a less than stellar pitcher by helping his team score runs and be a considerably better investment than a pitcher with a slightly lower ERA but no run production.
Paul the Octopus: Credible? July 11, 2010
Posted by tomflesher in Economics.Tags: binomial distribution, Paul the Octopus, statistics, World Cup
add a comment
Paul the Octopus (hatched 2008) is an octopus who correctly predicted 12 of 14 World Cup matches, including

Spain’s victory over the Dutch. Is his string of victories statistically significant?
First, I’m going to posit the null hypothesis that Paul is choosing randomly. As such, Paul’s proportion of correct choices should be .5 (
The standard error for proportions is
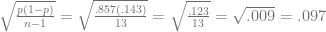
The t-value of an observation is
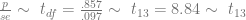
According to Texas A&M’s t Distribution Calculator, the probability (or p-value) of this result by chance alone is less than .01.
Using the binomial distribution with 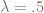
So, is Paul an oracle? Almost certainly not. However, not being a zoologist, I can’t explain what biases might be in play. I’d imagine it’s something like an attraction to contrast as well as a spurious correlation between octopus-attractive flags and success at soccer.
More on Home Runs Per Game July 9, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, Chow test, home runs, Japan, Japanese baseball, R, Rays, regression, replication
add a comment
In the previous post, I looked at the trend in home runs per game in the Major Leagues and suggested that the recent deviation from the increasing trend might have been due to the development of strong farm systems like the Tampa Bay Rays’. That means that if the same data analysis process is used on data in an otherwise identical league, we should see similar trends but no dropoff around 1995. As usual, for replication purposes I’m going to use Japan’s Pro Baseball leagues, the Pacific and Central Leagues. They’re ideal because, just like the American Major Leagues, one league uses the designated hitter and one does not. There are some differences – the talent pool is a bit smaller because of the lower population base that the leagues draw from, and there are only 6 teams in each league as opposed to MLB’s 14 and 16.
As a reminder, the MLB regression gave us a regression equation of

where 
Just examining the data on home runs per game from the Japanese leagues, the trend looks significantly differe nt. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
nt. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
After running the same regression with t=1 in 1950, I got these results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.2462 | 0.0992 | 2.481 | 0.0148 | 0.9852 |
| t | 0.0478 | 0.0062 | 7.64 | 1.63E-11 | 1 |
| tsq | -0.0006 | 0.00009 | -7.463 | 3.82E-11 | 1 |
| DH | 0.0052 | 0.0359 | 0.144 | 0.8855 | 0.1145 |
This equation shows two things, one that surprises me and one that doesn’t. The unsurprising factor is the switching of signs for the t variables – we expected that based on the shape of the data. The surprising factor is that the designated hitter rule is insignificant. We can only be about 11% sure it’s significant. In addition, this model explains less of the variation than the MLB version – while that explained about 56% of the variation, the Japanese model has an 
There’s a slightly interesting pattern to the residual home runs per game (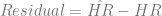
 it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
Incidentally, the Japanese league data is heteroskedastic (Breusch-Pagan test p-value .0796), so it might be better modeled using a generalized least squares formula, but doing so would have skewed the results of the replication.
In order to show that the parameters really are different, the appropriate test is Chow’s test for structural change. To clean it up, I’m using only the data from 1960 on. (It’s quick and dirty, but it’ll do the job.) Chow’s test takes

where 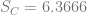
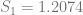
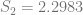





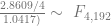


The critical value for 90% significance at 4 and 192 degrees of freedom would be 1.974 according to Texas A&M’s F calculator. That means we don’t have enough evidence that the parameters are different to treat them differently. This is probably an artifact of the small amount of data we have.
In the previous post, I looked at the trend in home runs per game in the Major Leagues and suggested that the recent deviation from the increasing trend might have been due to the development of strong farm systems like the Tampa Bay Rays’. That means that if the same data analysis process is used on data in an otherwise identical league, we should see similar trends but no dropoff around 1995. As usual, for replication purposes I’m going to use Japan’s Pro Baseball leagues, the Pacific and Central Leagues. They’re ideal because, just like the American Major Leagues, one league uses the designated hitter and one does not. There are some differences – the talent pool is a bit smaller because of the lower population base that the leagues draw from, and there are only 6 teams in each league as opposed to MLB’s 14 and 16.
As a reminder, the MLB regression gave us a regression equation of

where 
Just examining the data on home runs per game from the Japanese leagues, the trend looks significantly different. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
After running the same regression with t=1 in 1950, I got these results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.2462 | 0.0992 | 2.481 | 0.0148 | 0.9852 |
| t | 0.0478 | 0.0062 | 7.64 | 1.63E-11 | 1 |
| tsq | -0.0006 | 0.00009 | -7.463 | 3.82E-11 | 1 |
| DH | 0.0052 | 0.0359 | 0.144 | 0.8855 | 0.1145 |
This equation shows two things, one that surprises me and one that doesn’t. The unsurprising factor is the switching of signs for the t variables – we expected that based on the shape of the data. The surprising factor is that the designated hitter rule is insignificant. We can only be about 11% sure it’s significant. In addition, this model explains less of the variation than the MLB version – while that explained about 56% of the variation, the Japanese model has an 
There’s a slightly interesting pattern to the residual home runs per game ( it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
Incidentally, the Japanese league data is heteroskedastic (Breusch-Pagan test p-value .0796), so it might be better modeled using a generalized least squares formula, but doing so would have skewed the results of the replication.
In order to show that the parameters really are different, the appropriate test is Chow’s test for structural change. To clean it up, I’m using only the data from 1960 on. (It’s quick and dirty, but it’ll do the job.) Chow’s test takes
)/(k)}{(S_1+S_2)/(N_1+N_2-2k)} ~ F")
Back when it was hard to hit 55… July 8, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, home runs, R, regression, sabermetrics, Stuff Keith Hernandez Says, talent pool dilution, Willie Mays, Year of the Pitcher
add a comment
Last night was one of those classic Keith Hernandez moments where he started talking and then stopped abruptly, which I always like to assume is because the guys in the truck are telling him to shut the hell up. He was talking about Willie Mays for some reason, and said that Mays hit 55 home runs “back when it was hard to hit 55.” Keith coyly said that, while it was easy for a while, it was “getting hard again,” at which point he abruptly stopped talking.
Keith’s unusual candor about drug use and Mays’ career best of 52 home runs aside, this pinged my “Stuff Keith Hernandez Says” meter. After accounting for any time trend and other factors that might explain home run hitting, is there an upward trend? If so, is there a pattern to the remaining home runs?
The first step is to examine the data to see if there appears to be any trend. Just looking at it, there appears to be a messy U shape with a minimum around t=20, which indicates a quadratic trend. That means I want to include a term for time and a term for time squared.
Using the per-game averages for home runs from 1955 to 2009, I detrended the data using t=1 in 1955. I also had to correct for the effect of the designated hitter. That gives us an equation of the form
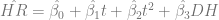
The results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.957 | 0.0328 | 29.189 | 0.0001 | 0.9999 |
| t | -0.0188 | 0.0028 | -6.738 | 0.0001 | 0.9999 |
| tsq | 0.0004 | 0.00005 | 8.599 | 0.0001 | 0.9999 |
| DH | 0.0911 | 0.0246 | 3.706 | 0.0003 | 0.9997 |
We can see that there’s an upward quadratic trend in predicted home runs that together with the DH rule account for about 56% of the variation in the number of home runs per game in a season (
Then, I needed to look at the difference between the predicted number of home runs per game and the actual number of home runs per game, which is accessible by subtracting
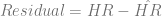
This represents the “abnormal” number of home runs per year. The question then becomes, “Is there a patt ern to the number of abnormal home runs?” There are two ways to answer this. The first way is to look at the abnormal home runs. Up until about t=40 (the mid-1990s), the abnormal home runs are pretty much scattershot above and below 0. However, at t=40, the residual jumps up for both leagues and then begins a downward trend. It’s not clear what the cause of this is, but the knee-jerk reaction is that there might be a drug use effect. On the other hand, there are a couple of other explanations.
ern to the number of abnormal home runs?” There are two ways to answer this. The first way is to look at the abnormal home runs. Up until about t=40 (the mid-1990s), the abnormal home runs are pretty much scattershot above and below 0. However, at t=40, the residual jumps up for both leagues and then begins a downward trend. It’s not clear what the cause of this is, but the knee-jerk reaction is that there might be a drug use effect. On the other hand, there are a couple of other explanations.
The most obvious is a boring old expansion effect. In 1993, the National League added two teams (the Marlins and the Rockies), and in 1998 each league added a team (the AL’s Rays and the NL’s Diamondbacks). Talent pool dilution has shown up in our discussion of hit batsmen, and I believe that it can be a real effect. It would be mitigated over time, however, by the establishment and development of farm systems, in particular strong systems like the one that’s producing good, cheap talent for the Rays.
Pinch Hitters from the Bullpen July 6, 2010
Posted by tomflesher in Baseball, Economics.Tags: binomial distribution, bullpen, Carlos Zambrano, Livan Hernandez, margin of error, Micah Owings, pinch hitter, sabermetrics
add a comment
Occasionally, a solid two-way player shows up in the majors. Carlos Zambrano is known as a solid hitter with a great arm (despite the occasional meltdown), and Micah Owings is the rare pitcher used as a pinch hitter. Even Livan Hernandez has 15 pinch-hit plate appearances (with 2 sacrifice bunts, 6 strikeouts, and a .077 average and .077 OBP, compared with a lifetime .227 average and .237 OBP).
Like Hernandez, Zambrano has a very different batting line as a pinch hitter than as a pitcher. In 24 plate appearances as a pinch hitter, Big Z is hitting only .087 with a .087 OBP, compared to his .243/.249 line when hitting as a pitcher. Since we see the same effect for both of these pitchers, it seems like there’s some sort of difference in hitting as a pinch hitter that causes the pitchers to be less mentally prepared. Of course, these numbers come from a very small sample.
On the other hand, Micah Owings hits .307/.331 as a pitcher, and a quite similar .250/.298 as a pinch hitter. What’s the difference? Owings has almost double Zambrano’s plate appearances as a pinch hitter with 47. That seems to show that maybe Owings’ larger sample size is what causes the similarity. How can this be tested rigorously?
As we did with Kevin Youkilis and his title of Greek God of Take Your Base, we can use the binomial distribution to see if it’s reasonable for Owings, Hernandez and Zambrano to hit so differently as pinch hitters. To figure out whether it’s reasonable or not, let’s limit our inquiry to OBP just because it’s a more inclusive measure and then assume that the batting average as a pitcher (i.e. the one with a larger sample size) is the pitcher’s “true” batting average and use that to represent the probability of getting on base. Each plate appearance is a Bernoulli trial with a binary outcome – we’ll call it a success if the player gets on base and a failure otherwise.
Under the binomial distribution, the probability of a player with OBP p getting on base k times in n plate appearances is:
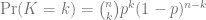
with
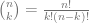
We’ll also need the margin of error for proportions. If p = OBP as pitcher, and we assume a t-distribution with over 100 plate appearances (i.e. degrees of freedom), then the margin of error is:
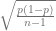
so that 95% of the time we’d expect the pinch hitting OBP to lie within

with
We’ll also need the margin of error for proportions. If p = OBP as pitcher, and we assume a t-distribution with over 100 plate appearances (i.e. degrees of freedom), then the margin of error is:
so that 95% of the time we’d expect the pinch hitting OBP to lie within
Let’s start with Owings. He has an OBP of .331 as a pitcher in 151 plate appearances, so the probability of having at most 14 times on base in 47 plate appearances is .3778. In other words, about 38% of the time, we’d expect a random string of 47 plate appearances to have 14 or fewer times on base. His 95% confidence interval is .254 to .408, so his .298 OBP as a pinch hitter is certainly statistically credible.
Owings is special, though. Hernandez, for example, has 994 plate appearances as a pitcher and a .237 OBP, with only one time on base in 15 plate appearances. It’s a very small sample, but the binomial distribution predicts he would have at most one time on base only about 9.8% of the time. His confidence interval is .210 to .264, which means that it’s very unlikely that he’d end up with an OBP of .077 unless there is some relevant difference between hitting as a pitcher and hitting as a pinch hitter.
Zambrano’s interval breaks down, too. He has 601 plate appearances as a pitcher with a .249 OBP, but an anemic .087 OBP (two hits) in 24 plate appearances as a pinch hitter. We’d expect 2 or fewer hits only 4% of the time, and 95% of the time we’d expect Big Z to hit between .214 and .284.
As a result, we can make two determinations.
- Zambrano and Hernandez are hitting considerably below expectations as pinch hitters. It’s likely, though not proven, that this is a pattern among most pitchers.
- Micah Owings is a statistical outlier from the pattern. It’s not clear why.
How often should Youk take his base? June 30, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, binomial distribution, Brett Carroll, Greek God of Take Your Base, hit batsmen, hit by pitch, Kevin Youkilis, R
add a comment
Kevin Youkilis is sometimes called “The Greek God of Walks.” I prefer to think of him as “The Greek God of Take Your Base,” since he seems to get hit by pitches at an alarming rate. In fact, this year, he’s been hit 7 times in 313 plate appearances. (Rickie Weeks, however, is leading the pack with 13 in 362 plate appearances. We’ll look at him, too.) There are three explanations for this:
- There’s something about Youk’s batting or his hitting stance that causes him to be hit. This is my preferred explanation. Youkilis has an unusual batting grip that thrusts his lead elbow over the plate, and as he swings, he lunges forward, which exposes him to being plunked more often.
- Youkilis is such a hitting machine that the gets hit often in order to keep him from swinging for the fences. This doesn’t hold water, to me. A pitcher could just as easily put him on base safely with an intentional walk, so unless there’s some other incentive to hit him, there’s no reason to risk ejection by throwing at Youkilis. This leads directly to…
- Youk is a jerk. This is pretty self-explanatory, and is probably a factor.
First of all, we need to figure out whether it’s likely that Kevin is being hit by chance. To figure that out, we need to make some assumptions about hit batsmen and evaluate them using the binomial distribution. I’m also excited to point out that Youk has been overtaken as the Greek God of Take Your Base by someone new: Brett Carroll. (more…)
Edwin Jackson, Fourth No-Hitter of 2010 June 25, 2010
Posted by tomflesher in Baseball, Economics.Tags: baseball-reference.com, BayesBall, Dallas Braden, Diamondbacks, Edwin Jackson, no-hitters, poisson distribution, Rays, Roy Halladay, Ubaldo Jimenez
2 comments
Tonight, Edwin Jackson of the Arizona Diamondbacks pitched a no-hitter against the Tampa Bay Rays. That’s the fourth no-hitter of this year, following Ubaldo Jimenez and the perfect games by Dallas Braden and Roy Halladay.
Two questions come to mind immediately:
- How likely is a season with 4 no-hitters?
- Does this mean we’re on pace for a lot more?
The second question is pretty easy to dispense with. Taking a look at the list of all no-hitters (which interestingly enough includes several losses), it’s hard to predict a pattern. No-hitters aren’t uniformly distributed over time, so saying that we’ve had 4 no-hitters in x games doesn’t tell us anything meaningful about a pace.
The first is a bit more interesting. I’m interested in the frequency of no-hitters, so I’m going to take a look at the list of frequencies here and take a page from Martin over at BayesBall in using the Poisson distribution to figure out whether this is something we can expect.
The Poisson distribution takes the form

where 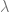

Using Martin’s numbers – 201506 opportunities for no-hitters and an average of 4112 games per season from 1961 to 2009 – I looked at the number of no-hitters since 1961 (120) and determined that an average season should return about 2.44876 no-hitters. That means
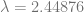
and

 Above is the distribution. p is the probability of exactly n no-hitters being thrown in a single season of 4112 games; cdf is the cumulative probability, or the probability of n or fewer no-hitters; p49 is the predicted number of seasons out of 49 (1961-2009) that we would expect to have n no-hitters; obs is the observed number of seasons with n no-hitters; cp49 is the predicted number of seasons with n or fewer no-hitters; and cobs is the observed number of seasons with n or fewer no-hitters.
Above is the distribution. p is the probability of exactly n no-hitters being thrown in a single season of 4112 games; cdf is the cumulative probability, or the probability of n or fewer no-hitters; p49 is the predicted number of seasons out of 49 (1961-2009) that we would expect to have n no-hitters; obs is the observed number of seasons with n no-hitters; cp49 is the predicted number of seasons with n or fewer no-hitters; and cobs is the observed number of seasons with n or fewer no-hitters.
It’s clear that 4 or even 5 no-hitters is a perfectly reasonable number to expect.
| 2.448760831 |
E-Reader Price Wars June 21, 2010
Posted by tomflesher in Economics.Tags: e-reader, elasticity, industrial organization, iPad, Kindle, Kobo, microeconomics, Nook, oligopoly, price theory, price wars, substitute goods
1 comment so far
Holy cow… two non-baseball updates in a row! I’ll have to fix that later on.
The news all over is that Amazon has cut the price of the Kindle from $259 to $189. By all accounts, this was prompted by the $60 price cut that Barnes & Noble gave the Nook ($259 to $199), which in turn was prompted by the low price of the Borders brand Kobo ($149). The availability of the iPad, an augmented substitute good for e-readers, will also potentially cause trouble, but the mere existence of the iPad doesn’t necessarily create downward price pressure in and of itself.
The Nook, Kindle, and Kobo are all extremely similar goods. I’d go so far as to say they’re perfect substitutes, if we consider this Kobo advertising table. Taking the American market, the price differential will disappear when the new price cuts take effect. The weight and thickness differences are negligible. The memory is similar. The only major difference is that the Kobo can use Bluetooth, while the Nook uses Wi-Fi and 3G, and the Kindle uses 3G. This difference is probably not going to result in significant market segmentation and no one will be likely to buy a Nook and a Kindle to take advantage of the Nook’s Wi-Fi capabilities, so it’s fair to consider these substitute goods with negative cross-elasticities of demand.
When prices for substitute goods with different producers move together, there are three options, two of which are sensible in a rational market:
- The firms could be colluding.
- The firms could be in a price war.
- The price change could be coincidental.
Coincidence isn’t very likely or very interesting, so we’ll only consider options 1 and 2. Collusion is fun to consider, but probably not relevant here. For one, when prices move due to collusion, they generally move up because firms are no longer attempting to price each other out of the market. Tacit collusion might be the reason that about $200 is the floor for 3G devices, but it’s unlikely to be the reason both firms cut prices.
The price war would explain the fact that the changes in price are negative and that they’re meeting at a similar level. Price war means increased competition. Assuming demand doesn’t change (it will), the firm with the lower price will sell its product. Assuming demand increases as price decreases (it will), each lowering of price should bring additional marginal consumers to the pool of people willing to buy these devices, so while prices fall, profits may or may not increase. If profits increase, however, it will likely be profitable to cut the price even further, because additional consumers can still be reached, and there will be downward pressure from other firms trying to keep up. As a result, price will approach the cost of production. Price won’t reach the marginal cost of production, however, since there are barriers to entry into the e-reader market (including specialized equipment, R&D for a new device since the current devices are protected by patents and trade secrets, and acquisition of rights to books).
A quick rule of thumb to see if we’re dealing with price war or collusion is to check the stock prices of the producer companies. All things being equal, if a price move increases stock price, then the move is the result of anti-competitive measures like collusion, because there will be higher profits. If a price move decreases stock price, then the move is likely to increase competition and lower profits will result. Here, to quote KTTC:
Barnes&Noble shares fell 55 cents, or 3.2 percent, to finish trading at $16.52. Amazon shares declined $3.28, or 2.6 percent, to $122.55.
(Apple’s stock, for the record, ticked down today without much else to explain the drop.) This is probably a pro-competition move. The likely winners fall into two groups:
- E-reader consumers, who will benefit from lower prices and more competition for amenities. The producers will likely be fighting for contracts with publishing houses, and a larger selection of books may be forthcoming.
- iPad users. E-readers are an imperfect substitute for the iPad, so in order for the iPad to remain a rational choice after the price cuts, it will have to become a better product to avoid losing out to people who will get a better value by buying a cheaper product. This should mean more of a focus on the differential aspects of the iPad like the App Store, iTunes, and (yes) iBooks.
This should be fun to watch.
Modeling Run Production June 19, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, economics, regression, run production, sports economics
add a comment
A baseball team can be thought of as a factory which uses a single crew to operate two machines. The first machine produces runs while the team bats, and the second machine produces outs while the team is on fields. This is a somewhat abstract way to look at the process of winning games, because ordinarily machines have a fixed input and a fixed output. In a box factory, the input comprises man-hours and corrugated board, and the output is a finished box. Here, the input isn’t as well-defined.
Runs are a function of total bases, certainly, but total bases are functions of things like hits, home runs, and walks. Basically, runs are a function of getting on base and of advancing people who are already on base. Obviously, the best measure of getting on base is On-Base Percentage, and Slugging Average (expected number of bases per at-bat) is a good measure of advancement.
OBP wraps up a lot of things – walks, hits, and hit-by-pitch appearances – and SLG corrects for the greater effects of doubles, triples, and home runs. That doesn’t account for a few other things, though, like stolen bases, sacrifice flies, and sacrifice hits. It also doesn’t reflect batter ability directly, but that’s okay – the stats we have should represent batter ability since the defensive side is trying to prevent run production. The model might look something like this, then:

This is the simplest model we can start with – each factor contributes a discrete number of runs. If we need to (and we probably will), we can add terms to capture concavity of the marginal effect of different stats, or (more likely) an interaction term for SLG and, say, SB, so that a stolen base is worth more on a team where you’re more likely to be brought home by a batter because he’s more likely to give you extra bases. As it is, however, we can test this model with linear regression. The details of it are behind the cut. (more…)
Cell Phone Insurance June 18, 2010
Posted by tomflesher in Economics.Tags: cell phones, insurance, risk, t-mobile
add a comment
Yesterday, I bought a new phone. It’s a Samsung Gravity 2 and with a two-year contract it cost $79.99 – it came with some accessories that aren’t of interest for now. The salesman tried to sell me insurance at a whopping $4.99 per month over the course of the contract. I told him I’d do $4.99 total, because I’m an economist, but he didn’t bite. (Sigh.)
How bad a deal is that? Well, I wanted to find out. First, I made some assumptions:
- The appropriate interest rate is 1.25 APY (.1042 MPY), which is roughly what my bank account is paying. I could put some amount of money in the bank right now and earn interest at that rate and it would be enough for me to pay the insurance. This is called the Net Present Value, and over 24 months at 4.99 per month it’s about $118.34.
- The likelihood of something happening to my phone is entirely random, so I can’t take it into account when determining whether the insurance is a good buy.
- My phone depreciates at a rate of
, where t is the number of the month (so this month is month 1, next month is month 2, etc.). This puts my discount rate at exactly my APY. It makes for a quick depreciation, with the phone getting within a dollar of its resale value within about 4 months. It caputres the quick drop in depreciation an the slow leveling off quite nicely.
- The definition of ‘good value’ is that at the time I turn in a damaged phone, its depreciated value is less than the cost of all the premiums I’ve paid. I chose to use the depreciated value rather than the cost of a new phone because it reflects that I’ve gotten some use out of the phone.
The long and the short of it is that if I damage the phone before about the 7th month, it’s a good value. After that, it’s all gravy for T-Mobile.
I ended up telling the salesman that I’m an economist and so paying that much for insurance is against my religion.
For those who are interested in the chart, it’s behind the cut. It lists monthly payment, month ordinal, the effective interest rate, present value of that payment, NPV as sum of the present values, the depreciated value of the phone, the depreciation factor, and the instantaneous depreciation.
