Is ‘luck’ persistent? May 25, 2011
Posted by tomflesher in Baseball, Economics.Tags: American League, Baseball, Pythagorean expectation, wins above expectation
2 comments
I’ve been listening to Scott Patterson’s The Quants in my spare time recently. One of the recurring jokes is Wall Street traders’ use of the word ‘Alpha’ (which usually represents abnormal returns in finance) to refer to a general quality of being skillful or having talent. That led me to think about an old concept I haven’t played with in a while – wins above expectation.
As a quick review, wins above expectation relate a team’s actual wins to its Pythagorean expectation. If the team wins more than expected, it has a positive WAE number, and if it loses more than expected, it has wins below expectation, or, equivalently, a negative WAE. It’s tempting to think of WAE as representing a sort of ‘alpha’ in the traders’ sense – since the Pythagorean Expectation involves groups of runs scored and runs allowed, it generates a probability that a team with a history represented by its runs scored/runs allowed stats will win a given game. If a team has a lot more wins than expected, it seems like that represents efficiency – scoring runs at crucial times, not wasting them on blowing out opponents – or especially skillful management. Alternatively, it could just be luck. Is there any way to test which it is?
It’s difficult. However, let’s break down what the efficiency factor would imply. In general, it would represent some combination of individual player skill (such as the alleged clutch hitting ability) and team chemistry, whether that boils down to on- or off-field factors. Assuming rosters don’t change much over the course of the year, then, efficiency also shouldn’t change much over the course of the year. Similarly, if a manager’s skill was the primary determinant of wins above expectation, then for teams that don’t change managers midyear, we wouldn’t expect much of a change throughout the course of the season. Most managers work up through the minors, so there probably isn’t a major on-the-job training effect to consider.
On the other hand, if wins above expectation are just luck, then we wouldn’t need to place any restrictions on them. Maybe they’d change. Maybe they wouldn’t. Who knows?
In order to test that idea, I pulled some data for the American League off Baseball Reference from last season. I split the season into pre- and post-All-Star Break sets and calculated the Pythagorean expectation (using the 1.81 exponent referred to in Wikipedia) for each team. I found WAE for each team in each session, then found each team’s ‘Alpha’ for that session by dividing WAE by the number of games played. Basically, I assumed that WAE represented extra win probability in some fashion and assumed it existed in every game at about the same level. The results:

As is evident from the table, a whopping 10 out of the 14 teams see a change in the sign of Alpha from before the All-Star Game to after the All-Star Game. The correlation coefficient of Alpha from pre- to post-All-Star is -.549, which is a pretty noisy correlation. (Note also that this very closely describes regression to the mean.) It’s not 0, but it’s also negative, implying one of two things: Either teams become less efficient and/or more badly managed, on average, after the break, or Alpha represents very little more than a realization of a random process, which might just as well be described as luck.
Home Run Derby: Does it ruin swings? December 15, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, Chris Young, Corey Hart, David Ortiz, Hanley Ramirez, home run derby, home runs, Matt Holliday, Miguel Cabrera, Nick Swisher, Vernon Wells
add a comment
Earlier this year, there was a lot of discussion about the alleged home run derby curse. This post by Andy on Baseball-Reference.com asked if the Home Run Derby is bad for baseball, and this Hardball Times piece agrees with him that it is not. The standard explanation involves selection bias – sure, players tend to hit fewer home runs in the second half after they hit in the Derby, but that’s because the people who hit in the Derby get invited to do so because they had an abnormally high number of home runs in the first half.
Though this deserves a much more thorough macro-level treatment, let’s just take a look at the density of home runs in either half of the season for each player who participated in the Home Run Derby. Those players include David Ortiz, Hanley Ramirez, Chris Young, Nick Swisher, Corey Hart, Miguel Cabrera, Matt Holliday, and Vernon Wells.
For each player, plus Robinson Cano (who was of interest to Andy in the Baseball-Reference.com post), I took the percentage of games before the Derby and compared it with the percentage of home runs before the Derby. If the Ruined Swing theory holds, then we’d expect

The table below shows that in almost every case, including Cano (who did not participate), the density of home runs in the pre-Derby games was much higher than the post-Derby games.
| Player | HR Before | HR Total | g(Games) | g(HR) | Diff |
| Ortiz | 18 | 32 | 0.54321 | 0.5625 | 0.01929 |
| Hanley | 13 | 21 | 0.54321 | 0.619048 | 0.075838 |
| Swisher | 15 | 29 | 0.537037 | 0.517241 | -0.0198 |
| Wells | 19 | 31 | 0.549383 | 0.612903 | 0.063521 |
| Holliday | 16 | 28 | 0.54321 | 0.571429 | 0.028219 |
| Hart | 21 | 31 | 0.549383 | 0.677419 | 0.128037 |
| Cabrera | 22 | 38 | 0.530864 | 0.578947 | 0.048083 |
| Young | 15 | 27 | 0.549383 | 0.555556 | 0.006173 |
| Cano | 16 | 29 | 0.537037 | 0.551724 | 0.014687 |
Is this evidence that the Derby causes home run percentages to drop off? Certainly not. There are some caveats:
- This should be normalized based on games the player played, instead of team games.
- It would probably even be better to look at a home run per plate appearance rate instead.
- It could stand to be corrected for deviation from the mean to explain selection bias.
- Cano’s numbers are almost identical to Swisher’s. They play for the same team. If there was an effect to be seen, it would probably show up here, and it doesn’t.
Once finals are up, I’ll dig into this a little more deeply.
Burnett, Hughes, and Playoff Rotations October 12, 2010
Posted by tomflesher in Baseball.Tags: A.J. Burnett, ALCS, ALDS, Andy Pettitte, Baseball, CC Sabathia, Dustin Moseley, Javier Vazquez, Joe Girardi, Phil Hughes, playoffs, rotations, world series
add a comment
There was much discussion of the Yankees’ specialized playoff rotation for the American League Division Series. As is conventional in the ALDS, Joe Girardi went with a three-man rotation. CC Sabathia and Andy Pettitte were locks; the third starter could have been A.J. Burnett, Javier Vazquez, or Dustin Moseley. Girardi went with young All-Star Phil Hughes in the third slot. That, of course, led to a sweep of the Minnestoa Twins to advance to the American League Championship Series.
First of all, I think it was probably the right decision. Hughes pitched 176 1/3 innings and gave up 82 earned runs, for an ER/IP of about .47. In Burnett’s 186 2/3 innings, he allowed 109 runs for an ER/IP of about .58. Surprisingly, Burnett allowed 9 unearned runs for a rate of about .048 unearned runs per inning pitched, whereas Hughes had only one unearned run for a rate of about .006, but of course those numbers probably don’t say anything significant. With 730 batters faced, he allowed about .11 earned runs per batter, or about 1 earned run every 9 batters faced, while Burnett’s 829 batters faced mean he had similar numbers of .13 earned runs per batter and 7.69 batters.
Most importantly to me, Hughes was much more predictable. Burnett faced, on average, 4.68 batters per inning pitched, with a variance of .92. Hughes faced over half a batter less per inning – 4.13 – and had a variance of .33. That means that not only did Burnett allow more baserunners, but when he was off, he was very off. Although the decision gets tougher when you have a higher BF/IP and a lower variance, Hughes was both better and more consistent in a similar number of innings, so he has to get the nod.
(That said, it’s shocking that such similar numbers produced one 18-8 pitcher and one 10-15 pitcher.)
The only question now is what order to pitch the announced four-man rotation for the ALCS. Of the choices,
OPTION 3
Sabathia
Hughes
Pettitte
Burnett
Sabathia
Hughes
Pettitte
seems clearly superior to me. It allows Burnett to start but avoids starting him twice, gets Hughes in play quite often, and puts the very reliable Andy Pettitte in play for a potential Game Seven. The linked article lists as a con that Pettitte is considered the number 2 starter, but at the Major League level a manager can’t be concerned with such frivolities. Besides, Pettitte is an established company man. I’d be surprised if he balked at a rotation that both maximized the team’s chances to win and put him in position to be the clutch hero.
Incidentally, this option lends itself to using the same rotation in the World Series. Option 2:
Sabathia
Pettitte
Hughes
Sabathia
Burnett
Pettitte
Sabathia
leaves Sabathia unavailable to start Game 1 of the World Series and might put Pettitte on short rest depending on the schedule to start Game 1. I can’t see starting the Series with Hughes or Burnett.
The 600 Home Run Almanac July 28, 2010
Posted by tomflesher in Baseball, Economics.Tags: 600 home runs, A-Rod, Alex Rodriguez, Babe Ruth, Barry Bonds, Baseball, baseball-reference.com, Hank Aaron, Jim Thome, Ken Griffey Jr., Manny Ramirez, probability, Sammy Sosa, statistics, Willie Mays
2 comments
People are interested in players who hit 600 home runs, at least judging by the Google searches that point people here. With that in mind, let’s take a look at some quick facts about the 600th home run and the people who have hit it.
Age: There are six players to have hit #600. Sammy Sosa was the oldest at 39 years old in 2007. Ken Griffey, Jr. was 38 in 2007, as were Willie Mays in 1969 and Barry Bonds in 2002. Hank Aaron was 37. Babe Ruth was the youngest at 36 in 1931. Alex Rodriguez, who is 35 as of July 27, will almost certainly be the youngest player to reach 600 home runs. If both Manny Ramirez and Jim Thome hang on to hit #600 over the next two to three seasons, Thome (who was born in August of 1970) will probably be 42 in 2012; Ramirez (born in May of 1972) will be 41 in 2013. (In an earlier post that’s when I estimated each player would hit #600.) If Thome holds on, then, he’ll be the oldest player to hit his 600th home run.
Productivity: Since 2000 (which encompasses Rodriguez, Ramirez, and Thome in their primes), the average league rate of home runs per plate appearances has been about .028. That is, a home run was hit in about 2.8% of plate appearances. Over the same time period, Rodriguez’ rate was .064 – more than double the league average. Ramirez hit .059 – again, over double the league rate. Thome, for his part, hit at a rate of .065 home runs per plate appearance. From 2000 to 2009, Thome was more productive than Rodriguez.
Standing Out: Obviously it’s unusual for them to be that far above the curve. There were 1,877,363 plate appearances (trials) from 2000 to 2009. The margin of error for a proportion like the rate of home runs per plate appearance is
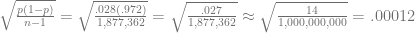
Ordinarily, we expect a random individual chosen from the population to land within the space of 
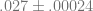
That means that all three of the players are well without that confidence interval. (However, it’s likely that home run hitting is highly correlated with other factors that make this test less useful than it is in other situations.)
Alex’s Drought: Finally, just how likely is it that Alex Rodriguez will go this long without a home run? He hit his last home run in his fourth plate appearance on July 22. He had a fifth plate appearance in which he doubled. Since then, he’s played in five games totalling 22 plate appearances, so he’s gone 23 plate appearances without a home run. Assuming his rate of .064 home runs per plate appearance, how likely is that? We’d expect (.064*23) = about 1.5 home runs in that time, but how unlikely is this drought?
The binomial distribution is used to model strings of successes and failures in tests where we can say clearly whether each trial ended in a “yes” or “no.” We don’t need to break out that tool here, though – if the probability of a home run is .064, the probability of anything else is .936. The likelihood of a string of 23 non-home runs is

It’s only about 22% likely that this drought happened only by chance. The better guess is that, as Rodriguez has said, he’s distracted by the switching to marked baseballs and media pressure to finally hit #600.
More on Home Runs Per Game July 9, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, Chow test, home runs, Japan, Japanese baseball, R, Rays, regression, replication
add a comment
In the previous post, I looked at the trend in home runs per game in the Major Leagues and suggested that the recent deviation from the increasing trend might have been due to the development of strong farm systems like the Tampa Bay Rays’. That means that if the same data analysis process is used on data in an otherwise identical league, we should see similar trends but no dropoff around 1995. As usual, for replication purposes I’m going to use Japan’s Pro Baseball leagues, the Pacific and Central Leagues. They’re ideal because, just like the American Major Leagues, one league uses the designated hitter and one does not. There are some differences – the talent pool is a bit smaller because of the lower population base that the leagues draw from, and there are only 6 teams in each league as opposed to MLB’s 14 and 16.
As a reminder, the MLB regression gave us a regression equation of

where 
Just examining the data on home runs per game from the Japanese leagues, the trend looks significantly differe nt. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
nt. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
After running the same regression with t=1 in 1950, I got these results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.2462 | 0.0992 | 2.481 | 0.0148 | 0.9852 |
| t | 0.0478 | 0.0062 | 7.64 | 1.63E-11 | 1 |
| tsq | -0.0006 | 0.00009 | -7.463 | 3.82E-11 | 1 |
| DH | 0.0052 | 0.0359 | 0.144 | 0.8855 | 0.1145 |
This equation shows two things, one that surprises me and one that doesn’t. The unsurprising factor is the switching of signs for the t variables – we expected that based on the shape of the data. The surprising factor is that the designated hitter rule is insignificant. We can only be about 11% sure it’s significant. In addition, this model explains less of the variation than the MLB version – while that explained about 56% of the variation, the Japanese model has an 
There’s a slightly interesting pattern to the residual home runs per game (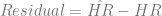
 it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
Incidentally, the Japanese league data is heteroskedastic (Breusch-Pagan test p-value .0796), so it might be better modeled using a generalized least squares formula, but doing so would have skewed the results of the replication.
In order to show that the parameters really are different, the appropriate test is Chow’s test for structural change. To clean it up, I’m using only the data from 1960 on. (It’s quick and dirty, but it’ll do the job.) Chow’s test takes

where 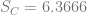
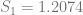
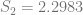





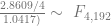


The critical value for 90% significance at 4 and 192 degrees of freedom would be 1.974 according to Texas A&M’s F calculator. That means we don’t have enough evidence that the parameters are different to treat them differently. This is probably an artifact of the small amount of data we have.
In the previous post, I looked at the trend in home runs per game in the Major Leagues and suggested that the recent deviation from the increasing trend might have been due to the development of strong farm systems like the Tampa Bay Rays’. That means that if the same data analysis process is used on data in an otherwise identical league, we should see similar trends but no dropoff around 1995. As usual, for replication purposes I’m going to use Japan’s Pro Baseball leagues, the Pacific and Central Leagues. They’re ideal because, just like the American Major Leagues, one league uses the designated hitter and one does not. There are some differences – the talent pool is a bit smaller because of the lower population base that the leagues draw from, and there are only 6 teams in each league as opposed to MLB’s 14 and 16.
As a reminder, the MLB regression gave us a regression equation of

where 
Just examining the data on home runs per game from the Japanese leagues, the trend looks significantly different. Instead of the rough U-shape that the MLB data showed, the Japanese data looks almost M-shaped with a maximum around 1984. (Why, I’m not sure – I’m not knowledgeable enough about Japanese baseball to know what might have caused that spike.) It reaches a minimum again and then keeps rising.
After running the same regression with t=1 in 1950, I got these results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.2462 | 0.0992 | 2.481 | 0.0148 | 0.9852 |
| t | 0.0478 | 0.0062 | 7.64 | 1.63E-11 | 1 |
| tsq | -0.0006 | 0.00009 | -7.463 | 3.82E-11 | 1 |
| DH | 0.0052 | 0.0359 | 0.144 | 0.8855 | 0.1145 |
This equation shows two things, one that surprises me and one that doesn’t. The unsurprising factor is the switching of signs for the t variables – we expected that based on the shape of the data. The surprising factor is that the designated hitter rule is insignificant. We can only be about 11% sure it’s significant. In addition, this model explains less of the variation than the MLB version – while that explained about 56% of the variation, the Japanese model has an 
There’s a slightly interesting pattern to the residual home runs per game ( it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
it isn’t as pronounced, this data also shows a spike – but the spike is at t=55, so instead of showing up in 1995, the Japan leagues spiked around the early 2000s. Clearly the same effect is not in play, but why might the Japanese leagues see the same effect later than the MLB teams? It can’t be an expansion effect, since the Japanese leagues have stayed constant at 6 teams since their inception.
Incidentally, the Japanese league data is heteroskedastic (Breusch-Pagan test p-value .0796), so it might be better modeled using a generalized least squares formula, but doing so would have skewed the results of the replication.
In order to show that the parameters really are different, the appropriate test is Chow’s test for structural change. To clean it up, I’m using only the data from 1960 on. (It’s quick and dirty, but it’ll do the job.) Chow’s test takes
)/(k)}{(S_1+S_2)/(N_1+N_2-2k)} ~ F")
Back when it was hard to hit 55… July 8, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, home runs, R, regression, sabermetrics, Stuff Keith Hernandez Says, talent pool dilution, Willie Mays, Year of the Pitcher
add a comment
Last night was one of those classic Keith Hernandez moments where he started talking and then stopped abruptly, which I always like to assume is because the guys in the truck are telling him to shut the hell up. He was talking about Willie Mays for some reason, and said that Mays hit 55 home runs “back when it was hard to hit 55.” Keith coyly said that, while it was easy for a while, it was “getting hard again,” at which point he abruptly stopped talking.
Keith’s unusual candor about drug use and Mays’ career best of 52 home runs aside, this pinged my “Stuff Keith Hernandez Says” meter. After accounting for any time trend and other factors that might explain home run hitting, is there an upward trend? If so, is there a pattern to the remaining home runs?
The first step is to examine the data to see if there appears to be any trend. Just looking at it, there appears to be a messy U shape with a minimum around t=20, which indicates a quadratic trend. That means I want to include a term for time and a term for time squared.
Using the per-game averages for home runs from 1955 to 2009, I detrended the data using t=1 in 1955. I also had to correct for the effect of the designated hitter. That gives us an equation of the form
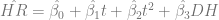
The results:
| Estimate | Std. Error | t-value | p-value | Signif | |
| B0 | 0.957 | 0.0328 | 29.189 | 0.0001 | 0.9999 |
| t | -0.0188 | 0.0028 | -6.738 | 0.0001 | 0.9999 |
| tsq | 0.0004 | 0.00005 | 8.599 | 0.0001 | 0.9999 |
| DH | 0.0911 | 0.0246 | 3.706 | 0.0003 | 0.9997 |
We can see that there’s an upward quadratic trend in predicted home runs that together with the DH rule account for about 56% of the variation in the number of home runs per game in a season (
Then, I needed to look at the difference between the predicted number of home runs per game and the actual number of home runs per game, which is accessible by subtracting
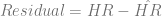
This represents the “abnormal” number of home runs per year. The question then becomes, “Is there a patt ern to the number of abnormal home runs?” There are two ways to answer this. The first way is to look at the abnormal home runs. Up until about t=40 (the mid-1990s), the abnormal home runs are pretty much scattershot above and below 0. However, at t=40, the residual jumps up for both leagues and then begins a downward trend. It’s not clear what the cause of this is, but the knee-jerk reaction is that there might be a drug use effect. On the other hand, there are a couple of other explanations.
ern to the number of abnormal home runs?” There are two ways to answer this. The first way is to look at the abnormal home runs. Up until about t=40 (the mid-1990s), the abnormal home runs are pretty much scattershot above and below 0. However, at t=40, the residual jumps up for both leagues and then begins a downward trend. It’s not clear what the cause of this is, but the knee-jerk reaction is that there might be a drug use effect. On the other hand, there are a couple of other explanations.
The most obvious is a boring old expansion effect. In 1993, the National League added two teams (the Marlins and the Rockies), and in 1998 each league added a team (the AL’s Rays and the NL’s Diamondbacks). Talent pool dilution has shown up in our discussion of hit batsmen, and I believe that it can be a real effect. It would be mitigated over time, however, by the establishment and development of farm systems, in particular strong systems like the one that’s producing good, cheap talent for the Rays.
Tough Losses July 8, 2010
Posted by tomflesher in Baseball.Tags: Baseball, baseball-reference.com, Dan Haren, Jon Niese, Roy Halladay, Roy Oswalt, Ubaldo Jimenez, weird lines, Year of the Pitcher, Yovani Gallardo
2 comments
Last night, Jonathon Niese pitched 7.2 innings of respectable work (6 hits, 3 runs, all earned, 1 walk, 8 strikeouts, 2 home runs, for a game score of 62) but still took the loss due to his unfortunate lack of run support – the Mets’ only run came in from an Angel Pagan solo homer. This is a prime example of what Bill James called a “Tough Loss”: a game in which the starting pitcher made a quality start but took a loss anyway.
There are two accepted measures of what a quality start is. Officially, a quality start is one with 6 or more innings pitched and 3 or fewer runs. Bill James’ definition used his game score statistic and used 50 as the cutoff point for a quality start. Since a pitcher gets 50 points for walking out on the mound and then adds to or subtracts from that value based on his performance, game score has the nice property of showing whether a pitcher added value to the team or not.
Using the game score definition, there were 393 losses in quality starts last year, including 109 by July 7th. Ubaldo Jimenez and Dan Haren led the league with 7, Roy Halladay had 6, and Yovani Gallardo (who’s quickly becoming my favorite player because he seems to show up in every category) was also up there with 6.
So far this year, though, it seems to be the Year of the Tough Loss. There have already been 230, and Roy Oswalt is already at the 6-tough-loss mark. Halladay is already up at 4. This is consistent with the talk of the Year of the Pitcher, with better pitching (and potentially less use of performance-enhancing drugs) leading to lower run support. That will require a bit more work to confirm, though.
How often should Youk take his base? June 30, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, baseball-reference.com, binomial distribution, Brett Carroll, Greek God of Take Your Base, hit batsmen, hit by pitch, Kevin Youkilis, R
add a comment
Kevin Youkilis is sometimes called “The Greek God of Walks.” I prefer to think of him as “The Greek God of Take Your Base,” since he seems to get hit by pitches at an alarming rate. In fact, this year, he’s been hit 7 times in 313 plate appearances. (Rickie Weeks, however, is leading the pack with 13 in 362 plate appearances. We’ll look at him, too.) There are three explanations for this:
- There’s something about Youk’s batting or his hitting stance that causes him to be hit. This is my preferred explanation. Youkilis has an unusual batting grip that thrusts his lead elbow over the plate, and as he swings, he lunges forward, which exposes him to being plunked more often.
- Youkilis is such a hitting machine that the gets hit often in order to keep him from swinging for the fences. This doesn’t hold water, to me. A pitcher could just as easily put him on base safely with an intentional walk, so unless there’s some other incentive to hit him, there’s no reason to risk ejection by throwing at Youkilis. This leads directly to…
- Youk is a jerk. This is pretty self-explanatory, and is probably a factor.
First of all, we need to figure out whether it’s likely that Kevin is being hit by chance. To figure that out, we need to make some assumptions about hit batsmen and evaluate them using the binomial distribution. I’m also excited to point out that Youk has been overtaken as the Greek God of Take Your Base by someone new: Brett Carroll. (more…)
Carlos Zambrano, Ace Pinch Hitter? June 21, 2010
Posted by tomflesher in Baseball.Tags: Baseball, baseball-reference.com, bullpen, Carlos Zambrano, Cubs, Joba Chamberlain, Lou Piniella, Micah Owings, RE24, relief, setup man, starter, Ubaldo Jimenez
1 comment so far
Earlier this year, Chicago Cubs manager Lou Piniella experimented with moving starting pitcher and relatively big hitter Carlos Zambrano to the bullpen, briefly making him the Major Leagues’ best-paid setup man. Zambrano is back in the rotation as of the beginning of June. I’m curious what the effect of moving him to the bullpen was.
The thing is that not only is Zambrano an excellent pitcher (though he was slumping at the time), he’s also a regarded as a very good hitter for a pitcher. He’s a career .237 hitter, with a slump last year at “only” .217 in 72 plate appearances (17th most in the National League), which was 6th in the National League among pitchers with at least 50 plate appearances. He didn’t walk enough (his OBP was 13th on the same list), but he was 9th of the 51 pitchers on the list in terms of Base-Out Runs Added (RE24) with about 5.117 runs below a replacement-level batter. Ubaldo Jimenez was also up there with a respectable .220 BA, .292 OBP, but -8.950 RE24.
It should be pointed out that pitcher RE24 is almost always negative for starters – the best RE24 on that list is Micah Owings with -2.069. Zambrano’s run contribution was negative, sure, but it was a lot less negative than most starters. Zambrano also lost a bit of flexibility as an emergency pinch hitter (something that Owings is going through right now due to his recent move to the bullpen) – he’s more valuable as a reliever, so they won’t use him to pinch hit. As a result, he loses at-bats, and that not only keeps him from amassing hits. It also allows him to get rusty.
It’s hard to precisely value the loss of Zambrano’s contribution, although he’s already on pace for -6.1 batting RE24. It’s likely, in my opinion, that his RE24 will rise as he continues hitting over the course of the year. His pitching value is also negative, however, which is unusual. He’s always been very respectable among Cubs starters. It’s possible that although he was pitching very well in relief, the fact that he has the ability to go long means that it’s inefficient to use him as a reliever. This is the opposite of, say, Joba Chamberlain, who is overpowering in relief but struggles as a starter.
As a starter, Zambrano has never been a net loss of runs. He needs to stay out of the bullpen, and Joba needs to stay there.
Modeling Run Production June 19, 2010
Posted by tomflesher in Baseball, Economics.Tags: Baseball, economics, regression, run production, sports economics
add a comment
A baseball team can be thought of as a factory which uses a single crew to operate two machines. The first machine produces runs while the team bats, and the second machine produces outs while the team is on fields. This is a somewhat abstract way to look at the process of winning games, because ordinarily machines have a fixed input and a fixed output. In a box factory, the input comprises man-hours and corrugated board, and the output is a finished box. Here, the input isn’t as well-defined.
Runs are a function of total bases, certainly, but total bases are functions of things like hits, home runs, and walks. Basically, runs are a function of getting on base and of advancing people who are already on base. Obviously, the best measure of getting on base is On-Base Percentage, and Slugging Average (expected number of bases per at-bat) is a good measure of advancement.
OBP wraps up a lot of things – walks, hits, and hit-by-pitch appearances – and SLG corrects for the greater effects of doubles, triples, and home runs. That doesn’t account for a few other things, though, like stolen bases, sacrifice flies, and sacrifice hits. It also doesn’t reflect batter ability directly, but that’s okay – the stats we have should represent batter ability since the defensive side is trying to prevent run production. The model might look something like this, then:

This is the simplest model we can start with – each factor contributes a discrete number of runs. If we need to (and we probably will), we can add terms to capture concavity of the marginal effect of different stats, or (more likely) an interaction term for SLG and, say, SB, so that a stolen base is worth more on a team where you’re more likely to be brought home by a batter because he’s more likely to give you extra bases. As it is, however, we can test this model with linear regression. The details of it are behind the cut. (more…)
